TCP/IP 协议栈在 Linux 内核中的运行时序分析-付世荣-SA20225160
时间:2022-04-03 16:29
调研要求
1.在深入理解Linux内核任务调度(中断处理、softirg、tasklet、wq、内核线程等)机制的基础上,分析梳理send和recv过程中TCP/IP协议栈相关的运行任务实体及相互协作的时序分析。
2.编译、部署、运行、测评、原理、源代码分析、跟踪调试等。
3.应该包括时序图。
1.Linux概述
1.1 Linux操作系统架构简介
Linux操作系统总体上由Linux内核和GNU系统构成,具体来讲由4个主要部分构成,即Linux内核、Shell、文件系统和应用程序。内核、Shell和文件系统构成了操作系统的基本结构,使得用户可以运行程序、管理文件并使用系统。
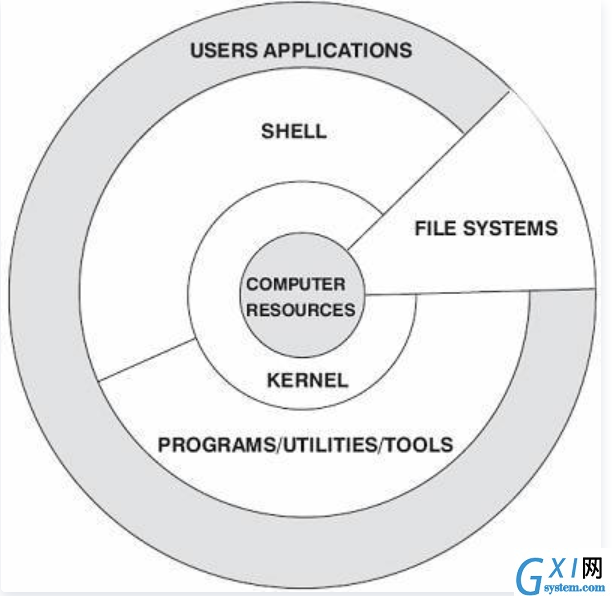
内核是操作系统的核心,具有很多最基本功能,如虚拟内存、多任务、共享库、需求加载、可执行程序和TCP/IP网络功能。我们所调研的工作,就是在Linux内核层面进行分析
一个主流的清晰的网络分层模型是OSI七层模型。如下图所示,它自上而下由应用层,表示层,会话层,传输层,网络层,数据链路层,物理层组成。但是这种分层只适用于学习,而不适用于实践。
1.2 分层模型
1.2.1OSI模型和TCP/IP模型
OSI(Open System Interconnect),即开放式系统互联。 一般都叫OSI参考模型,是ISO组织在1985年研究的网络互联模型。该体系结构标准定义了网络互联的七层框架(物理层、数据链路层、网络层、传输层、会话层、表示层和应用层),即OSI开放系统互连参考模型。OSI参考模型中每个层次接收到上层传递过来的数据后都要将本层次的控制信息加入数据单元的头部,一些层次还要将校验和等信息附加到数据单元的尾部,这个过程叫做封装。
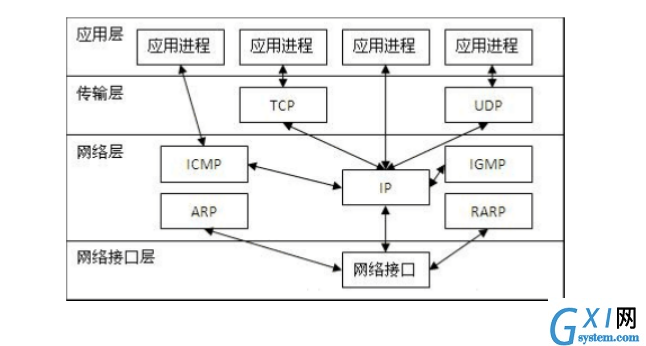
1.2.2 Linux中的网络模型
linux网络栈的层次结构非常清晰,并没有按照OSI七层模型来实现,而是压缩并扩展了一些层。从上而下,依次为应用层,系统调用接口层,协议无关接口层,网络栈层,设备无关接口层,设备驱动层。因为linux的网络栈中的socket是继承自BSD的,socket插口为应用层使用网络服务提供了简单的方法,它屏蔽了具体的下层协议族的差异。下面重点说一下中间的4层。
-
系统调用接口层。系统调用接口层提供了socket接口的系统调用。
-
协议无关接口层。为什么会有这一层呢?协议无关指的又是什么无关?首先呢,我们得知道,网络世界里是有很有种协议族的,比如我们最常用的tcp/ipv4协议族,但是除此之外还有很多协议族存在,比如netlink,unix等,因此,为了使用上的方便,抽象了一个协议无关接口层,只需要在创建socket时,传入对应的参数,就能创建出对应的协议族socket类型。具体的可以看一下socket函数的参数:socket(int domain, int type, int protocol);第一个参数就定义了使用的协议族,ipv4的?ipv6的?unix的?等等。第二个参数就是指定socket类型,是流式套接字还是用户数据报?还是原始套接字?一般来说,前两个参数选定了,就能确定一个socket的类型和使用的传输层协议了,如流式套接字对应使用tcp/ip中的tcp协议,用户数据包对应使用tcp/ip中的udp协议。
-
网络栈层。这一层就是具体的各类协议的实现了。包括传输层和网络层。对于我们最经常使用的tcp/ip来说,传输层主要包括tcp和udp协议。网络层就是ip协议。这一部分也是这个系列重点需要解释的,后面仔细说。
-
设备无关接口层。这一层夹在网络栈和驱动层之间,至于为什么会有这么一层存在?可以想象一下,网络设备种类多样,当收到数据包时,怎么传递给网络栈?如果没有设备无关接口层的抽象,势必会导致两层之间的调用花样百出,因此,有必要抽象出设备无关层,如驱动向上的传递接口,通用设备表示等。从这个设计来看,给我们很多启示,联想上面的协议无关接口层,可以看出,在一对多这种情况下,设计一个通用层会有很多好处。
2 测试代码简介
客户端代码:
#include <stdio.h> /* perror */
#include <stdlib.h> /* exit */
#include <sys/types.h> /* WNOHANG */
#include <sys/wait.h> /* waitpid */
#include <string.h> /* memset */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <errno.h>
#include <arpa/inet.h>
#include <netdb.h> /* gethostbyname */
?
#define true 1
#define false 0
?
#define PORT 3490 /* Server的端口 */
#define MAXDATASIZE 100 /* 一次可以读的最大字节数 */
?
int main(int argc, char *argv[])
{
int sockfd, numbytes;
char buf[MAXDATASIZE];
struct hostent *he; /* 主机信息 */
struct sockaddr_in server_addr; /* 对方地址信息 */
if (argc != 2)
{
fprintf(stderr, "usage: client hostname\n");
exit(1);
}
?
/* get the host info */
if ((he = gethostbyname(argv[1])) == NULL)
{
/* 注意:获取DNS信息时,显示出错需要用herror而不是perror */
/* herror 在新的版本中会出现警告,已经建议不要使用了 */
perror("gethostbyname");
exit(1);
}
?
if ((sockfd = socket(PF_INET, SOCK_STREAM, 0)) == -1)
{
perror("socket");
exit(1);
}
?
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(PORT); /* short, NBO */
server_addr.sin_addr = *((struct in_addr *)he->h_addr_list[0]);
memset(&(server_addr.sin_zero), 0, 8); /* 其余部分设成0 */
?
if (connect(sockfd, (struct sockaddr *)&server_addr,
sizeof(struct sockaddr)) == -1)
{
perror("connect");
exit(1);
}
?
if ((numbytes = recv(sockfd, buf, MAXDATASIZE, 0)) == -1)
{
perror("recv");
exit(1);
}
?
buf[numbytes] = ‘\0‘;
printf("Received: %s", buf);
close(sockfd);
?
return true;
}
服务端代码:
#include <stdio.h> /* perror */
#include <stdlib.h> /* exit */
#include <sys/types.h> /* WNOHANG */
#include <sys/wait.h> /* waitpid */
#include <string.h> /* memset */
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <errno.h>
#include <arpa/inet.h>
#include <netdb.h> /* gethostbyname */
?
#define true 1
#define false 0
?
#define MYPORT 3490 /* 监听的端口 */
#define BACKLOG 10 /* listen的请求接收队列长度 */
?
int main()
{
int sockfd, new_fd; /* 监听端口,数据端口 */
struct sockaddr_in sa; /* 自身的地址信息 */
struct sockaddr_in their_addr; /* 连接对方的地址信息 */
unsigned int sin_size;
?
if ((sockfd = socket(PF_INET, SOCK_STREAM, 0)) == -1)
{
perror("socket");
exit(1);
}
?
sa.sin_family = AF_INET;
sa.sin_port = htons(MYPORT); /* 网络字节顺序 */
sa.sin_addr.s_addr = INADDR_ANY; /* 自动填本机IP */
memset(&(sa.sin_zero), 0, 8); /* 其余部分置0 */
?
if (bind(sockfd, (struct sockaddr *)&sa, sizeof(sa)) == -1)
{
perror("bind");
exit(1);
}
?
if (listen(sockfd, BACKLOG) == -1)
{
perror("listen");
exit(1);
}
?
/* 主循环 */
while (1)
{
sin_size = sizeof(struct sockaddr_in);
new_fd = accept(sockfd,
(struct sockaddr *)&their_addr, &sin_size);
if (new_fd == -1)
{
perror("accept");
continue;
}
?
printf("Got connection from %s\n",
inet_ntoa(their_addr.sin_addr));
if (fork() == 0)
{
/* 子进程 */
if (send(new_fd, "Hello, world!\n", 14, 0) == -1)
perror("send");
close(new_fd);
exit(0);
}
?
close(new_fd);
?
/*清除所有子进程 */
while (waitpid(-1, NULL, WNOHANG) > 0)
;
}
close(sockfd);
return true;
}
3 应用层
3.1 socket
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。在 Linux 系统中,socket 属于文件系统的一部分,网络通信可以被看作是对文件的读 取,使得对网络的控制和对文件的控制一样方便。
3.2 socket 的创建
Socket()本质上是一个glibc中的函数,执行实际上是是调用sys_socketcall()系统调用。sys_socketcall()是几乎所有socket相关函数的入口,即是说,bind,connect等等函数都需要sys_socketcall()作为入口。
而对于创建socket,自然会在switch中调用到sys_socket()系统调用,而这个函数仅仅是调用sock_create()来创建socket和sock_map_fd()来与文件系统进行关联。
sock_create() 内部的主要结构是 socket 结构体,其主要负责socket 结构体的创建(sock_alloc())和初始化,以及指定socket套接字的类型和操作函数集,然后分配一个文件描述符作为socket套接字的操作句柄,该描述符就是我们常说的套接字描述符。socket 的创建主要是分配一个inode 对象来说实现的。inode 对面内部有一个 union 类型变量,里面包含了各种类型的结构体,这里采用的 socket 类型,然后二者建立关联,inode中的union采用socket,socket结构中的inode指针指向该inode对象。
inet_create() 内部的主要结构是 sock 结构体,sock 结构体比socket 结构更显复杂,其使用范围也更为广泛,socket 结构体是一个通用的结构,不涉及到具体的协议,而sock 结构则与具体的协议挂钩,属于具体层面上的一个结构。inet_create 函数的主要功能则是创建一个 sock 结构(kmalloc())然后根据上层传值下来的协议(通常是类型与地址族组合成成对应的协议)进行初始化。最后将创建好的 sock 结构插入到 sock 表中。
3.3 send
对于send函数,首先TCP是面向连接的,会有三次握手,建立连接成功,即代表两个进程可以用send和recv通信,作为发送信息的一方,肯定是接收到了从用户程序发送数据的请求,即send函数的参数之一,接收到数据后,若数据的大小超过一定长度,肯定不可能直接发送除去,因此,首先要对数据分段,将数据分成一个个的代码段,其次,TCP协议位于传输层,有响应的头部字段,在传输时肯定要加在数据前,数据也就被准备好了。当然,TCP是没有能力直接通过物理链路发送出去的,要想数据正确传输,还需要一层一层的进行。所以,最后一步是将数据传递给网络层,网络层再封装,然后链路层、物理层,最后被发送除去。
当调用send()函数时,内核封装send()为sendto(),然后发起系统调用。其实也很好理解,send()就是sendto()的一种特殊情况,而sendto()在内核的系统调用服务程序为sys_sendto。
__sys_sendto函数作用:
1.通过fd获取了对应的struct socket
2.创建了用来描述要发送的数据的结构体struct msghdr。
3.调用了sock_sendmsg来执行实际的发送。
sys_sendto构建完这些后,调用sock_sendmsg继续执行发送流程,传入参数为struct msghdr和数据的长度。忽略中间的一些不重要的细节,sock_sendmsg继续调用sock_sendmsg(),sock_sendmsg()最后调用struct socket->ops->sendmsg,即对应套接字类型的sendmsg()函数,所有的套接字类型的sendmsg()函数都是 sock_sendmsg,该函数首先检查本地端口是否已绑定,无绑定则执行自动绑定,而后调用具体协议的sendmsg函数。
3.4 recv
对于recv函数,与send类似,自然也是recvfrom的特殊情况,调用的也就是__sys_recvfrom,整个函数的调用路径与send非常类似,__sys_recvfrom调用了sock_recvmsg来接收数据,整个函数实际调用的是sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);,同样,根据tcp_prot结构的初始化,调用的其实是tcp_rcvmsg.接受函数比发送函数要复杂得多,因为数据接收不仅仅只是接收,tcp的三次握手也是在接收函数实现的,所以收到数据后要判断当前的状态,是否正在建立连接等,根据发来的信息考虑状态是否要改变,在这里,我们仅仅考虑在连接建立后数据的接收。这里共维护了三个队列:prequeue、backlog、receive_queue,分别为预处理队列,后备队列和接收队列,在连接建立后,若没有数据到来,接收队列为空,进程会在sk_busy_loop函数内循环等待,知道接收队列不为空,并调用函数数skb_copy_datagram_msg将接收到的数据拷贝到用户态,实际调用的是__skb_datagram_iter,这里同样用了struct msghdr *msg来实现。
4 传输层
4.1 send
tcp_sendmsg实际上调用的是tcp_sendmsg_locked函数,在tcp_sendmsg_locked中,完成的是将所有的数据组织成发送队列,这个发送队列是struct sock结构中的一个域sk_write_queue,这个队列的每一个元素是一个skb,里面存放的就是待发送的数据。然后调用了tcp_push()函数。在tcp协议的头部有几个标志字段:URG、ACK、RSH、RST、SYN、FIN,tcp_push中会判断这个skb的元素是否需要push,如果需要就将tcp头部字段的push置一,置一的过程如下:
static void tcp_push(struct sock *sk, int flags, int mss_now,
int nonagle, int size_goal)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
?
skb = tcp_write_queue_tail(sk);
if (!skb)
return;
if (!(flags & MSG_MORE) || forced_push(tp))
tcp_mark_push(tp, skb);
?
tcp_mark_urg(tp, flags);
?
if (tcp_should_autocork(sk, skb, size_goal)) {
?
/* avoid atomic op if TSQ_THROTTLED bit is already set */
if (!test_bit(TSQ_THROTTLED, &sk->sk_tsq_flags)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING);
set_bit(TSQ_THROTTLED, &sk->sk_tsq_flags);
}
/* It is possible TX completion already happened
* before we set TSQ_THROTTLED.
*/
if (refcount_read(&sk->sk_wmem_alloc) > skb->truesize)
return;
}
?
if (flags & MSG_MORE)
nonagle = TCP_NAGLE_CORK;
?
__tcp_push_pending_frames(sk, mss_now, nonagle);
}
首先struct tcp_skb_cb结构体存放的就是tcp的头部,头部的控制位为tcp_flags,通过tcp_mark_push会将skb中的cb,也就是48个字节的数组,类型转换为struct tcp_skb_cb,这样位于skb的cb就成了tcp的头部。
struct sk_buff {
...
char cb[48] __aligned(8);
...
struct tcp_skb_cb {
__u32 seq; /* Starting sequence number */
__u32 end_seq; /* SEQ + FIN + SYN + datalen */
__u8 tcp_flags; /* tcp头部标志,位于第13个字节tcp[13]) */
......
};
然后,tcp_push调用了__tcp_push_pending_frames(sk, mss_now, nonagle);随后又调用了tcp_write_xmit来发送数据:
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss,
int nonagle)
{
if (tcp_write_xmit(sk, cur_mss, nonagle, 0,
sk_gfp_mask(sk, GFP_ATOMIC)))
tcp_check_probe_timer(sk);
}
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
unsigned int tso_segs, sent_pkts;
int cwnd_quota;
int result;
bool is_cwnd_limited = false, is_rwnd_limited = false;
u32 max_segs;
/*统计已发送的报文总数*/
sent_pkts = 0;
......
/*若发送队列未满,则准备发送报文*/
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
if (unlikely(tp->repair) && tp->repair_queue == TCP_SEND_QUEUE) {
/* "skb_mstamp_ns" is used as a start point for the retransmit timer */
skb->skb_mstamp_ns = tp->tcp_wstamp_ns = tp->tcp_clock_cache;
list_move_tail(&skb->tcp_tsorted_anchor, &tp->tsorted_sent_queue);
tcp_init_tso_segs(skb, mss_now);
goto repair; /* Skip network transmission */
}
if (tcp_pacing_check(sk))
break;
tso_segs = tcp_init_tso_segs(skb, mss_now);
BUG_ON(!tso_segs);
/*检查发送窗口的大小*/
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota) {
if (push_one == 2)
/* Force out a loss probe pkt. */
cwnd_quota = 1;
else
break;
}
.......
}
tcp_write_xmit位于tcpoutput.c中,它实现了tcp的拥塞控制,然后调用了tcp_transmit_skb(sk, skb, 1, gfp)传输数据,实际上调用的是__tcp_transmit_skb。
tcp_transmit_skb是tcp发送数据位于传输层的最后一步,这里首先对TCP数据段的头部进行了处理,然后调用了网络层提供的发送接口icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);实现了数据的发送,自此,数据离开了传输层,传输层的任务也就结束了。
4.2 recv
tcp_v4_rcv函数为TCP的总入口,数据包从IP层传递上来,进入该函数;其协议操作函数结构如下所示,其中handler即为IP层向TCP传递数据包的回调函数,设置为tcp_v4_rcv;tcp_v4_rcv函数只要做以下几个工作:(1) 设置TCP_CB (2) 查找控制块 (3)根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理,TCP_LISTEN状态处理 (4) 接收TCP段;之后,调用的也就是__sys_recvfrom,整个函数的调用路径与send非常类似。整个函数实际调用的是sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags),同样,根据tcp_prot结构的初始化,调用的其实是tcp_rcvmsg .接受函数比发送函数要复杂得多,因为数据接收不仅仅只是接收,tcp的三次握手也是在接收函数实现的,所以收到数据后要判断当前的状态,是否正在建立连接等,根据发来的信息考虑状态是否要改变,在这里,我们仅仅考虑在连接建立后数据的接收。
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
......
if (sk_can_busy_loop(sk) && skb_queue_empty(&sk->sk_receive_queue) &&
(sk->sk_state == TCP_ESTABLISHED))
sk_busy_loop(sk, nonblock);
lock_sock(sk);
.....
if (unlikely(tp->repair)) {
err = -EPERM;
if (!(flags & MSG_PEEK))
goto out;
if (tp->repair_queue == TCP_SEND_QUEUE)
goto recv_sndq;
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out;
......
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
......
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
if (err) {
/* Exception. Bailout! */
if (!copied)
copied = -EFAULT;
break;
}
}
*seq += used;
copied += used;
len -= used;
tcp_rcv_space_adjust(sk);
}
这里共维护了三个队列:prequeue、backlog、receive_queue,分别为预处理队列,后备队列和接收队列,在连接建立后,若没有数据到来,接收队列为空,进程会在sk_busy_loop函数内循环等待,知道接收队列不为空,并调用函数数skb_copy_datagram_msg将接收到的数据拷贝到用户态,实际调用的是__skb_datagram_iter,这里同样用了struct msghdr *msg来实现。
int __skb_datagram_iter(const struct sk_buff *skb, int offset,
struct iov_iter *to, int len, bool fault_short,
size_t (*cb)(const void *, size_t, void *, struct iov_iter *),
void *data)
{
int start = skb_headlen(skb);
int i, copy = start - offset, start_off = offset, n;
struct sk_buff *frag_iter;
/* 拷贝tcp头部 */
if (copy > 0) {
if (copy > len)
copy = len;
n = cb(skb->data + offset, copy, data, to);
offset += n;
if (n != copy)
goto short_copy;
if ((len -= copy) == 0)
return 0;
}
/* 拷贝数据部分 */
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int end;
const skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
WARN_ON(start > offset + len);
end = start + skb_frag_size(frag);
if ((copy = end - offset) > 0) {
struct page *page = skb_frag_page(frag);
u8 *vaddr = kmap(page);
if (copy > len)
copy = len;
n = cb(vaddr + frag->page_offset +
offset - start, copy, data, to);
kunmap(page);
offset += n;
if (n != copy)
goto short_copy;
if (!(len -= copy))
return 0;
}
start = end;
}
5 网络层
5.1 send
入口函数是ip_queue_xmit,ip_queue_xmit是 ip 层提供给 tcp 层发送回调函数。ip_queue_xmit()完成面向连接套接字的包输出,当套接字处于连接状态时,所有从套接字发出的包都具有确定的路由, 无需为每一个输出包查询它的目的入口,可将套接字直接绑定到路由入口上, 这由套接字的目的缓冲指针(dst_cache)来完成。ip_queue_xmit()首先为输入包建立IP包头, 经过本地包过滤器后,再将IP包分片输出(ip_fragment)。
int ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl)
{
return __ip_queue_xmit(sk,skb,fl,iner)sk(sk)-->tos);
}
函数ip_queue_xmit调用函数__ip_queue_xmit
/* Note: skb->sk can be different from sk, in case of tunnels */
int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl,
__u8 tos)
{
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
struct ip_options_rcu *inet_opt;
struct flowi4 *fl4;
struct rtable *rt;
struct iphdr *iph;
int res;
/* Skip all of this if the packet is already routed,
* f.e. by something like SCTP.
*/
rcu_read_lock();
inet_opt = rcu_dereference(inet->inet_opt);
fl4 = &fl->u.ip4;
//獲取skb中的路由緩存
rt = skb_rtable(skb);
if (rt)
goto packet_routed;
/* Make sure we can route this packet. */
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (!rt) {
__be32 daddr;
Skb_rtable(skb)获取 skb 中的路由缓存,然后判断是否有缓存,如果有缓存就直接进行packet_routed函数,否则就 执行ip_route_output_ports查找路由缓存。
/* TODO : should we use skb->sk here instead of sk ? */ skb->priority = sk->sk_priority; skb->mark = sk->sk_mark; res = ip_local_out(net, sk, skb); rcu_read_unlock(); return res;
最后调用 ip_local_out得到返回值res:
int ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
int err;
err = __ip_local_out(net, sk, skb);
if (likely(err == 1))
err = dst_output(net, sk, skb);
return err;
}
同函数ip_queue_xmit一样,ip_local_out函数内部调用__ip_local_out。
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
iph->tot_len = htons(skb->len);
ip_send_check(iph);
/* if egress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_out(sk, skb);
if (unlikely(!skb))
return 0;
skb->protocol = htons(ETH_P_IP);
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,
net, sk, skb, NULL, skb_dst(skb)->dev,
dst_output);
}
ip_finish__output函数内部调用了__ip_finish_output函数
static int __ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
unsigned int mtu;
#if defined(CONFIG_NETFILTER) && defined(CONFIG_XFRM)
/* Policy lookup after SNAT yielded a new policy */
if (skb_dst(skb)->xfrm) {
IPCB(skb)->flags |= IPSKB_REROUTED;
return dst_output(net, sk, skb);
}
#endif
mtu = ip_skb_dst_mtu(sk, skb);
if (skb_is_gso(skb))
return ip_finish_output_gso(net, sk, skb, mtu);
if (skb->len > mtu || (IPCB(skb)->flags & IPSKB_FRAG_PMTU))
return ip_fragment(net, sk, skb, mtu, ip_finish_output2);
return ip_finish_output2(net, sk, skb);
}
如果分片就调用ip_fragment,否则就调用ip_fragment函数:
static int ip_fragment(struct net *net, struct sock *sk, struct sk_buff *skb,
unsigned int mtu,
int (*output)(struct net *, struct sock *, struct sk_buff *))
{
struct iphdr *iph = ip_hdr(skb);
if ((iph->frag_off & htons(IP_DF)) == 0)
return ip_do_fragment(net, sk, skb, output);
if (unlikely(!skb->ignore_df ||
(IPCB(skb)->frag_max_size &&
IPCB(skb)->frag_max_size > mtu))) {
IP_INC_STATS(net, IPSTATS_MIB_FRAGFAILS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
htonl(mtu));
kfree_skb(skb);
return -EMSGSIZE;
}
return ip_do_fragment(net, sk, skb, output);
}
gdp验证:
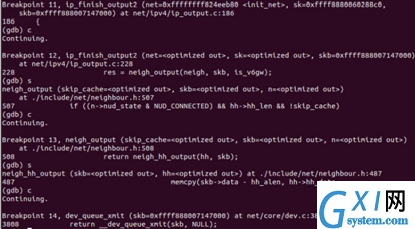
5.2 recv
IP 层的入口函数在 ip_rcv 函数。该函数首先会做包括 package checksum 在内的各种检查,如果需要的话会做 IP defragment(将多个分片合并),然后 packet 调用已经注册的 Pre-routing netfilter hook ,完成后最终到达 ip_rcv_finish 函数。ip_rcv_finish 函数会调用 ip_router_input 函数,进入路由处理环节。它首先会调用 ip_route_input 来更新路由,然后查找 route,决定该 package 将会被发到本机还是会被转发还是丢弃
/*
* IP receive entry point
*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
if (skb == NULL)
return NET_RX_DROP;
return NF_HOOK(NFPROTO_IPV4, NF_INET_pre_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
}
ip_rcv_finish函数:
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
int ret;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_rcv(skb);
if (!skb)
return NET_RX_SUCCESS;
ret = ip_rcv_finish_core(net, sk, skb, dev);
if (ret != NET_RX_DROP)
ret = dst_input(skb);
return ret;
}
ip_local_deliver函数:
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
ip_protocol_deliver_rcu函数:
void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol)
{
const struct net_protocol *ipprot;
int raw, ret;
resubmit:
raw = raw_local_deliver(skb, protocol);
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
if (!ipprot->no_policy) {
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
kfree_skb(skb);
return;
}
nf_reset_ct(skb);
}
ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv,
skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
} else {
if (!raw) {
if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
__IP_INC_STATS(net, IPSTATS_MIB_INUNKNOWNPROTOS);
icmp_send(skb, ICMP_DEST_UNREACH,
ICMP_PROT_UNREACH, 0);
}
kfree_skb(skb);
} else {
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
consume_skb(skb);
}
}
}
gdb验证:
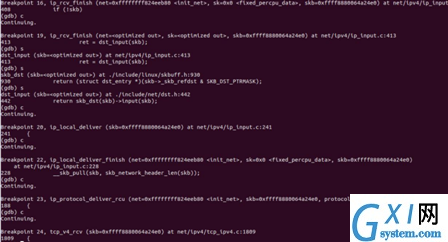
6 数据链路层
6.1 send
调用__dev_queue_xmit:
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev){
.......
* Check this and shot the lock. It is not prone from deadlocks.
*Either shot noqueue qdisc, it is even simpler 8)
*/
if (dev->flags & IFF_UP) {
int cpu = smp_processor_id(); /* ok because BHs are off */
if (txq->xmit_lock_owner != cpu) {
if (dev_xmit_recursion())
goto recursion_alert;
skb = validate_xmit_skb(skb, dev, &again);
if (!skb)
goto out;
HARD_TX_LOCK(dev, txq, cpu);
if (!netif_xmit_stopped(txq)) {
dev_xmit_recursion_inc();
skb = dev_hard_start_xmit(skb, dev, txq, &rc);
dev_xmit_recursion_dec();
if (dev_xmit_complete(rc)) {c
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
}
调用dev_hard_start_xmit函数获取skb。
struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *dev,
struct netdev_queue *txq, int *ret)
{
struct sk_buff *skb = first;
int rc = NETDEV_TX_OK;
while (skb) {
struct sk_buff *next = skb->next;
skb_mark_not_on_list(skb);
rc = xmit_one(skb, dev, txq, next != NULL);
if (unlikely(!dev_xmit_complete(rc))) {
skb->next = next;
goto out;
}
skb = next;
if (netif_tx_queue_stopped(txq) && skb) {
rc = NETDEV_TX_BUSY;
break;
}
}
out:
*ret = rc;
return skb;
}
gdb调试:
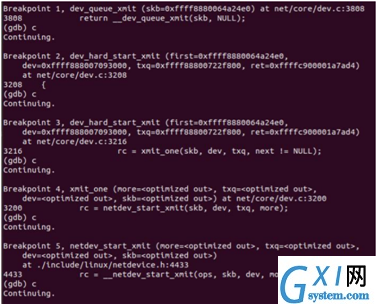
6.2 recv
入口函数net_rx_action
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies +
usecs_to_jiffies(netdev_budget_usecs);
int budget = netdev_budget;
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto out;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
napi_gro_receive函数
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
gro_result_t ret;
skb_mark_napi_id(skb, napi);
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb);
ret = napi_skb_finish(dev_gro_receive(napi, skb), skb);
trace_napi_gro_receive_exit(ret);
return ret;
}
时序图

















本类排行
今日推荐






热门手游
-
地下道中文版

版本:v1.0.6
大小:89.16MB
日期:2024-04-23
-
逃脱游戏GHOST手机版

版本:v1.1
大小:58.37MB
日期:2024-04-23
-
索尼克狂欢Plus破解版

版本:v1.1.0
大小:259.83MB
日期:2024-04-23
-
我的地盘我说了算免广告版

版本:v113
大小:206.4MB
日期:2024-04-23
-
周五夜放克无广告版

版本:1.1.1
大小:93.41MB
日期:2024-04-23
-
刺激飞跃摩托新版

版本:v306.1.0.3018
大小:95.7M
日期:2024-04-23