Redis(八) LRU Cache
时间:2022-04-03 14:45
Redis(八)—— LRU Cache
在计算机中缓存可谓无所不在,无论还是应用还是操作系统中,为了性能都需要做缓存。然缓存必然与缓存算法息息相关,LRU就是其中之一。笔者在最先接触LRU是大学学习操作系统时的了解到的,至今已经非常模糊。在学习Redis时,又再次与其相遇,这里将这块内容好好梳理总结。
LRU(Least Recently Used)是缓存算法家族的一员——最近最少使用算法,类似的算法还有FIFO(先进先出)、LIFO(后进先出)等。因为缓存的选择一般都是用内存(RAM)或者计算机中的L1甚至L2高速缓存,无疑这些存储器都是有大小限制,使用的代价都非常高昂,不可能将所有需要缓存的数据都缓存起来,需要使用特定的算法,比如LRU将不常用的数据驱逐出缓存,以腾出更多的空间存储更有价值的数据。
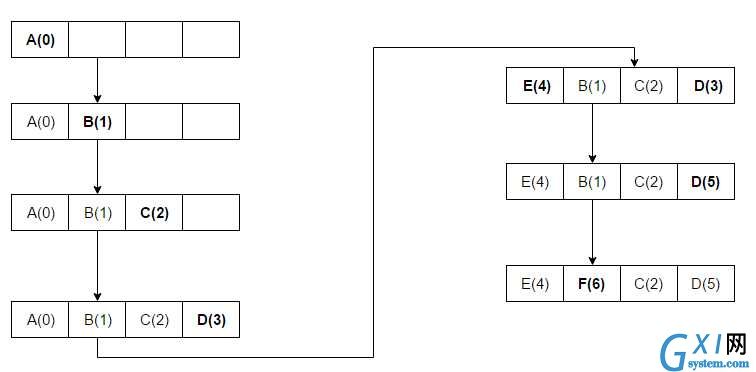
上图引用上描述LRU算法的图。其中A是最近最少被使用,所以当缓存E时,根据LRU的特征,驱逐A,存储E。
在LRU中最核心的部分是"最近最少",所以必然需要对缓存数据的访问(读和写)做跟踪记录——即什么时候使用了什么数据!
本文先介绍Redis中的LRU特点,再介绍如何自实现一个LRU。
- Redis中的LRU
- 自实现LRU Cache
- Guava Cache
Redis中的LRU
1.内存限制
前文中介绍Redis是基于内存的K-V数据结构服务器。Redis在存储方面有内存容量限制。在Redis中通过maxmemory配置设置Redis可以使用的最大内存。如:
maxmemory 100mb以上配置则限制Redis可以使用的最大内存为100M。当设置为0时,表示没有进行内存限制。
上述说到Redis的内存限制问题,如果Redis使用的内存达到限制,再进行写入操作,Redis该如何处理?
Redis中有很多驱逐策略——Eviction Policies,当内存达到限制时,Redis会使用其配置的策略对内存中的数据进行驱逐回收,释放内存空间,以便存储待写入的数据。
2.驱逐策略
Redis中有以下的内存策略可供选择
- noeviction:没有任何驱逐策略,当内存达到限制,如果执行的命令需要使用更多的内存,则直接返回错误;
- allkeys-lru:使用lru算法,即驱逐最近最少被使用的键,回收空间以便写入新的数据;
- volatile-lru:使用lru算法,即驱逐最近最少被使用的被设置过期的键,回收空间以便写入新的数据;
- allkeys-random:使用随机算法,即随机驱逐任意的键,回收空间以便写入新的数据
- volatile-random:使用随机算法,即随机驱逐被设置的过期键,回收空间以便写入新的数据;
- volatile-ttl:驱逐只有更短的有效期的被设置的过期键,回收空间以便写入新的数据;
其中volatile-lru、volatile-random和volatile-ttl策略驱逐,如果没有可驱逐的键,则结果和noeviction策略一样,都是返回错误。
Notes:
在Redis中的LRU算法并不是完全精确的LRU实现,只是近似的LRU算法——即通过采样一些键,然后从采样中按照LRU驱逐。如果要实现完全精确的LRU算法,势必需要跨越整个Redis内存进行统计,这样对性能就有折扣。在性能和LRU之间的trade off。
关于更多详细内容,请参考:
自实现LRU Cache
上述介绍了Redis中对于内存限制实现其LRU策略,下面笔者综合平时所学,简单实现一个LRU Cache,加深对其理解。
实现LRU Cache的关键点在于:
- Cache目的为了提高查找的性能,所以如何设计Cache的数据结构保证查找的算法复杂度比较低是关键;
- LRU算法决定了必须要对Cache中的所有数据进行年龄追踪,即LRU中的数据的访问(读和写)都需要实时记录;
对于第一点,能够实现快速查找的数据结构Map是必选,映射表结构具有天然的快速查找的特点。
对于第二点,要么对每个元素维护一份访问信息——每个元素都有一个访问时间字段,要么以特定的顺序表示其访问信息——列表前后顺序表示访问时间排序。
基于以上分析,JDK中提供了Map和访问顺序的数据结构——LinkedHashMap。这里为了简单,基于LinkedHashMap实现。当然感兴趣还可以基于Map接口自实现,不过都是大同小异。
当然还可以使用第二点中的第一种方式,但是这样需要跨越整个缓存空间,遍历比较每个元素的访问时间,代价高昂。
先定义LRUCache的接口:
public interface LRUCache<K, V> {
V put(K key, V value);
V get(K key);
int getCapacity();
int getCurrentSize();
}然后继承实现LinkedHashMap,在LinkedHashMap中有布尔accessOrder属性控制其顺序:true表示按照访问顺序,false表示按照插入顺序。 在构造LinkedHashMap时需要设置true,表示按照访问顺序进行迭代。
重写removeEldestEntry方法:如果当前缓存中的元素个数大于缓存的容量,则返回true,表示需要移除元素。
/**
* 基于{@link LinkedHashMap}实现的LRU Cache,该缓存是非线程安全,需要caller保证同步。
* 原理:
* 1.LinkedHashMap中使用双向循环链表的顺序有两种,其中访问顺序表示最近最少未被访问的顺序
* 2.基于HashMap,所以get的算法复杂度O(1)
*
* @author huaijin
*/
public final class LRUCacheBaseLinkedHashMap<K, V>
extends LinkedHashMap<K, V> implements LRUCache<K, V>{
private static final int DEFAULT_CAPACITY = 16;
private static final float DEFAULT_LOAD_FACTOR = 0.75F;
/**
* 缓存大小
*/
private int capacity;
public LRUCacheBaseLinkedHashMap() {
this(DEFAULT_CAPACITY);
}
public LRUCacheBaseLinkedHashMap(int capacity) {
this(capacity, DEFAULT_LOAD_FACTOR);
}
public LRUCacheBaseLinkedHashMap(int capacity, float loadFactor) {
super(capacity, loadFactor, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
@Override
public V put(K key, V value) {
Objects.requireNonNull(key, "key must not be null.");
Objects.requireNonNull(value, "value must not be null.");
return super.put(key, value);
}
@Override
public String toString() {
List<String> sb = new ArrayList<>();
Set<Map.Entry<K, V>> entries = entrySet();
for (Map.Entry<K, V> entry : entries) {
sb.add(entry.getKey().toString() + ":" + entry.getValue().toString());
}
return String.join(" ", sb);
}
@Override
public int getCapacity() {
return capacity;
}
@Override
public int getCurrentSize() {
return size();
}
}如果对LinkedHashMap不是很熟悉,请移步至
Guava Cache
对于使用Cache而言,Guava工具库中的Guava Cache是一个非常不错的选择。其优势在于:
- 适用性:缓存在很多场景中都适用,无论是大到操作系统、数据库、浏览器和大型网站等等,小到平时开发的小型应用、移动app等等;
- 多样性:Guava Cache提供多种方式载入数据至缓存;
- 可驱逐:内存资源是宝贵的,这点无可否认!所以缓存数据需要置换策略,Guava Cache从多种维度提供了不同的策略;
详细情况可以参考:。在Guava Cache中的驱逐策略有基于大小的策略,该策略就是LRU的实现:
Cache<String, String> guavaCache = CacheBuilder.newBuilder()
.maximumSize(5)
.build();当Cache的容量达到5个时,如果再往缓存中写入数据,Cache将淘汰最近最少被使用的数据。
测试如下案例如下:
@Test
public void testLRUGuavaCacheBaseSize() throws ExecutionException {
Cache<String, String> guavaCache = CacheBuilder.newBuilder()
.maximumSize(5)
.build();
guavaCache.put("1", "1");
guavaCache.put("2", "2");
guavaCache.put("3", "3");
guavaCache.put("4", "4");
guavaCache.put("5", "5");
printGuavaCache("原cache:", guavaCache);
guavaCache.getIfPresent("1");
guavaCache.put("6", "6");
printGuavaCache("put一次后cache:", guavaCache);
}执行结果:
原cache:2:2 3:3 1:1 5:5 4:4
put一次后cache:6:6 3:3 1:1 5:5 4:4因为数据1被get一次,导致2是最近最少被使用,当put 6时,将2淘汰驱逐。
总结
缓存目的就是为了提高访问速度以带来性能上质的提升。但是缓存的容量和命中率却是从反比。
基于内存存储数据,无论应用本地缓存,还是分布式缓存服务器甚至操作系统,都需要考虑存储容量的限制对命中率的影响。采用合适缓存算法,对提高缓存命中率至为关键。



























