SparkSQL学习案例:使用DataFrame和Dataset操作json数据
时间:2022-03-06 22:51
一、测试数据集(奥特曼.json)

二、源代码
1 import org.apache.spark.sql.SparkSession
2
3 //在Scala中,样例类在编译时会默认实现Product特质
4 case class Ultraman(name: String, age: BigInt, address: Array[String])
5
6 object DatasetAndDataFrameExample {
7
8 def main(args: Array[String]): Unit = {
9
10 //实例化SparkSession
11 val spark = SparkSession
12 .builder()
13 .master("local[*]")
14 .appName("DatasetAndDataFrameExample")
15 .getOrCreate()
16
17 //为避免影响输出结果,设置日志打印等级为"WARN"
18 spark.sparkContext.setLogLevel("WARN")
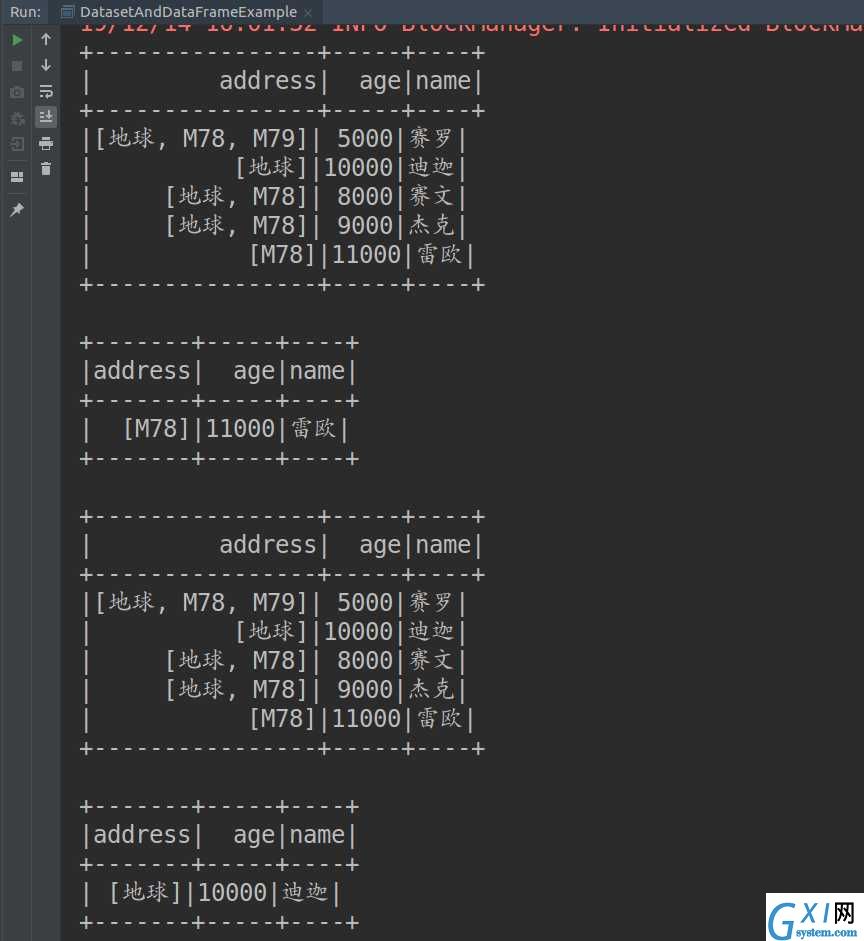
19
20 import spark.implicits._
21
22 val df1 = spark.read.json("/home/liuyin/IdeaProjects/Spark/src/main/scala/chap07_SparkSQL/奥特曼.json")
23 df1.show()
24 df1.filter($"address" === Array("M78")).filter($"age" > 10000).show()
25
26 val ds1 = spark.read.json("/home/liuyin/IdeaProjects/Spark/src/main/scala/chap07_SparkSQL/奥特曼.json").as[Ultraman]
27 ds1.show()
28 ds1.filter(_.name == "迪迦").show()
29
30 spark.stop()
31 }
32 }
三、输出结果
















本类排行
今日推荐






热门手游
-
胡闹厨房手机版

版本:v0.9.3.1
大小:84.25MB
日期:2024-05-19
-
soupsoup magazine安卓版

版本:v1.1
大小:28.13MB
日期:2024-05-19
-
套圈盘老板官方版

版本:v1.0.5
大小:88.49MB
日期:2024-05-19
-
Rykby锯齿陷阱官方版

版本:v1.0.7
大小:16.93MB
日期:2024-05-19
-
Poppy Playtime汉化版

版本:2.0
大小:56.57MB
日期:2024-05-19
-
像素火影破解版

版本:v1.00.42
大小:222.66MB
日期:2024-05-18