mysql之存储过程和函数
时间:2022-03-16 11:44
1. 变量
系统变量:
定义:变量由系统提供,不是用户定义,属于服务器层面
查看所有变量:SELECT global | session variables;

查看满足条件的部分系统变量:SELECT global | session variables like ‘%char%‘;
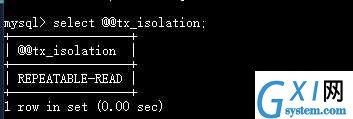
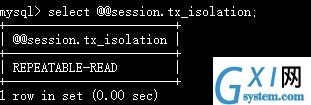
查看某个系统变量:select @@系统变量名 或者 select @@[session]global.系统变量名;如select @@tx_isolation查看事务隔离级别
为变量赋值:set 系统变量名=值

系统全局变量(GLOBAL):
# 查看全部的系统全局变量 SELECT GLOBAL VARIABLES; # 查看部分系统全局变量 SELECT GLOBAL VARIABLES LIKE ‘%char%‘;
# 其他同上方式
作用域:服务器每次启动将为所有的全局变量赋初值,针对于所有会话有效,但不能跨重启;
会话变量(SESSION):
作用域:变量仅对于当前会话连接有效。
自定义变量:
使用步骤:声明、赋值、使用(查看,比较,运算符)
作用域:针对于当前会话有效。
# 赋值操作符:=或:= SET @用户变量名=值; SET @用户变量名:=值; SElECT @用户变量名:=值;


局部变量:
作用域:仅仅在定义它的begin end之间有效
# 声明 DECLARE 变量名 类型; DECLARE 变量名 类型 DEFAULT 值;
# 赋值 SET 局部变量=值 SET 局部变量:=值
# begin与end中根据查询结果赋值 declare v1 int default 0; # 声明并初始化 select count(*) into v1 from table_name ;
2. 存储过程
存储过程类似于python中的函数,完成了一组操作,只对外暴露引用名,隐藏了具体实现细节
定义:一组预先编译好的SQL语句的集合,理解成批处理语句
优点:
1. 提高了代码的重用性;
2. 简化了操作;
3.减少了编译次数并且减少了和数据库服务器的连接次数,提高了效率
创建语法:
create procedure 存储过程名(参数列表)
begin
存储过程体(一组合法有效的SQL语句)
end
参数模式:在mysql中提供了三组参数模式
| IN | 该参数可以用作输入,也就是说该参数需要调用方传入值 |
| OUT | 该参数可以作为输出,类似python中return之后的返回值 |
| INOUT | 该参数即可以作为参数又可以作为参数输出 |
其他:存储过程体只有一条语句时, begin和end可以省略;否则就需要使用delimiter来重新设置语句结束符
调用存储过程:call 存储过程名(参数)
实例演示:
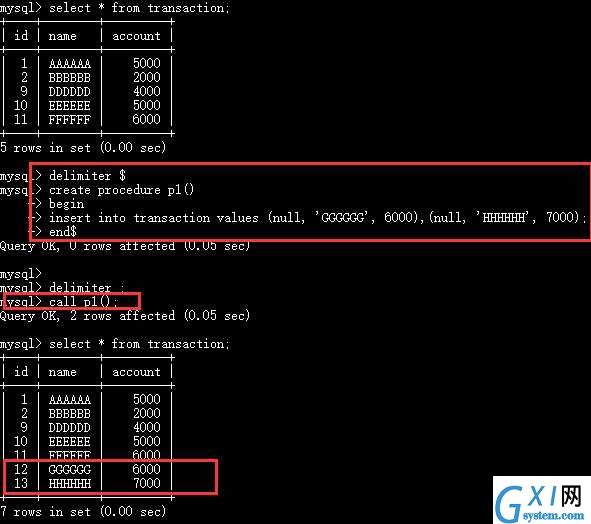
1. 无参,向指定表插入数据
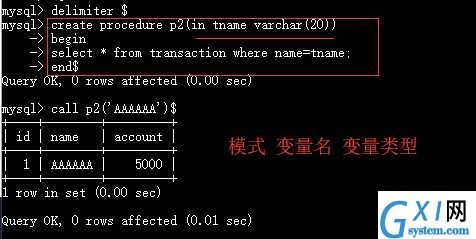
2. IN模式,
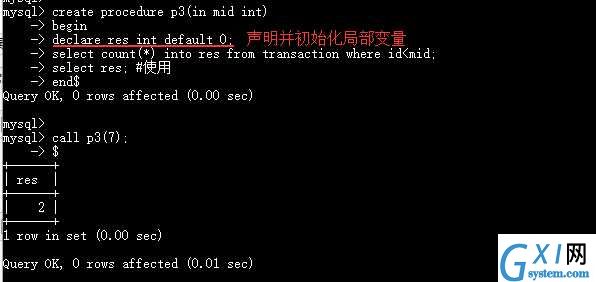
3.OUT模式,根据指定name查询其财产并返回
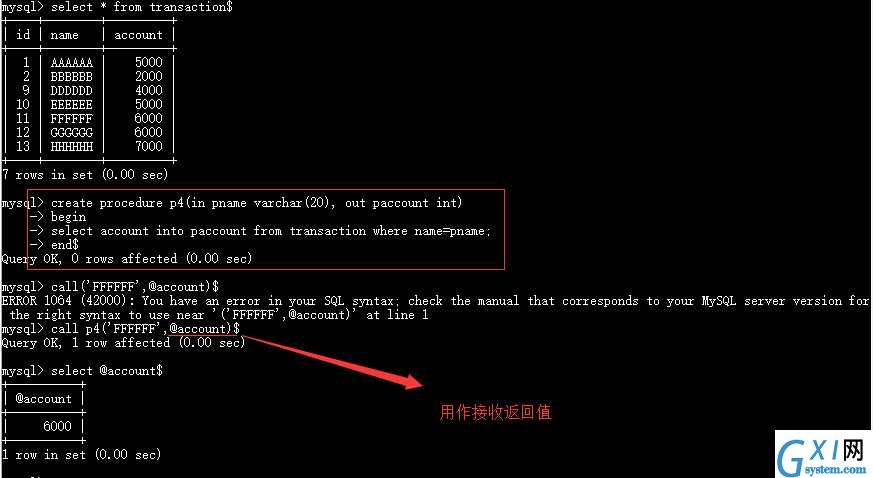
4. INOUT模式,参数既能作为返回值,也能作为接收值,在调用该存储过程的时候,就需要传入已经初始化的两个用户变量来完成。

3.函数
和存储过程大致相同,区别在于:
1. 存储过程可以有0个或者多个返回,适合批量插入,批量更新,
2. 有且仅有1个返回,适合做处理数据后返回一个结果。
语法格式:
create function 函数名(参数列表) returns 返回类型
begin
函数体
end
注意:参数列表包含两个部分:参数名及参数类型;函数体中肯定会有return语句,如果没有会报错
调用语法:
select 函数名(参数);
实例:
delimiter $
create function myfun(mid int) returns int
begin
declare res int default 0;
select count(*) into res from transaction where id<mid;
return res;
end$
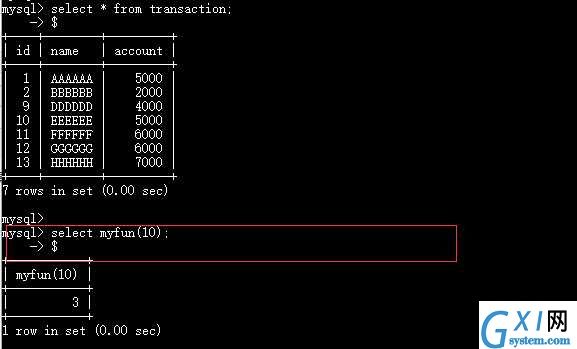
查看与删除函数:
# 查看 show create function myfun; # 删除 drop function myfun;
4. 流程控制结构
顺序结构:程序从上向下依次执行
分支结构:程序从两条或多条路径选择一条去执行
循环结构:在满足一定条件下,重复执行一段代码
case结构:可以作为独立语句来使用,放在begin end中
#应用一:做等值的布尔判断,类似于switch #语法: case 变量或表达式 when 要判断的值 then 返回的值或语句; when 要判断的值 then 返回的值或语句; ... else 返回的值或语句; end case;
# 应用二:做区间判断 case when 判断的条件表达式1 then 返回的值; when 判断的条件表达式1 then 返回的值; ... else 返回的值; end case;
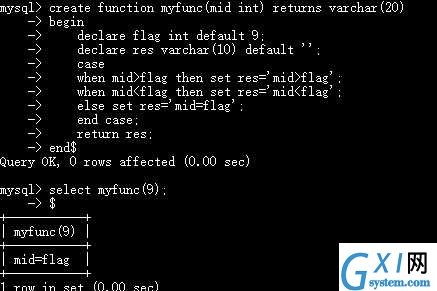
# 传入mid,与flag(9)作比较
create function myfunc(mid int) returns varchar(20)
begin
declare flag int default 9;
declare res varchar(10) default ‘‘;
case
when mid>flag then set res=‘mid>flag‘;
when mid<flag then set res=‘mid<flag‘;
else set res=‘mid=flag‘;end case;
return res;
end$
if结构:实现多重分支, 只能用在begin end中
语法:
if 条件1 then 语句1; elseif 条件2 then 语句2; ..... [else 语句n;] # 可选 end if;
循环结构:
分类有while、loop、repeat
循环控制:iterate类似于continue、leave类似于break
语法:
# while
【标签】: while 循环条件 do 循环体; end while 【标签】 ;
# loop 死循环
【标签:】loop 循环体; end loop 【标签】;
# repeat类似于do while
【标签:】repeat 循环体 until 结束循环的条件 end repeat 【标签】;
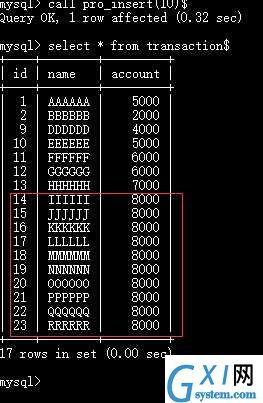
实例演示:
批量插入
delimiter $
create procedure pro_insert(IN count INT)
begin
declare i int default 0;
declare last_letter char default ‘‘; #transaction最后一行数据的name值的第一位字符,如‘AAAAAA‘则取‘A‘
declare max_ascii int default 0; #transaction表的最后一行数据的name值的第一位字符的ASCII码
select substr(name, 1, 1) into last_letter from transaction where id=(select max(id) from transaction); #为last_letter变量赋值
set max_ascii=ASCII(last_letter); #为max_ascii赋值
_insert: while i<count do # 循环的别名为_insert
set max_ascii=max_ascii+1;
set i=i+1;
insert into transaction values(null, repeat(char(max_ascii), 6), 8000);
end while _insert;
end$
















本类排行
今日推荐
-
阅读笔趣免费小说极速版

版本:v1.3
大小:9.8M
日期:2024-04-28
-
全网小说在线版

版本:v1.3.4
大小:19.6M
日期:2024-04-28
-
文汇官方版

版本:v7.3.2
大小:36.8M
日期:2024-04-28
-
全本免费阅读器免费版

版本:v3.4.7
大小:32.7M
日期:2024-04-28
-
爱沂水精简版

版本:v0.1.36
大小:35.1M
日期:2024-04-28
-
中网市场发布经典版

版本:v1.3.5
大小:6.7M
日期:2024-04-28
热门手游
-
夏天的乐队正式版

版本:v1.0.1
大小:60.15MB
日期:2024-04-29
-
可靠快递官方版

版本:v1.4121
大小:302.77MB
日期:2024-04-29
-
TotallyReliableDeliveryService中文版

版本:v1.4121
大小:302.77MB
日期:2024-04-29
-
罗布泊和朋友完整版

版本:v1.1
大小:55.47MB
日期:2024-04-29
-
女鬼模拟器汉化版

版本:v1.0
大小:0.33MB
日期:2024-04-29
-
老鼠无限刀超超变官服版

版本:v1.3.170
大小:226.31MB
日期:2024-04-29