hbase-16-写入流程
时间:2022-05-11 13:05
Hbase 写入流程大致分为三个步骤:

1.客户端请求
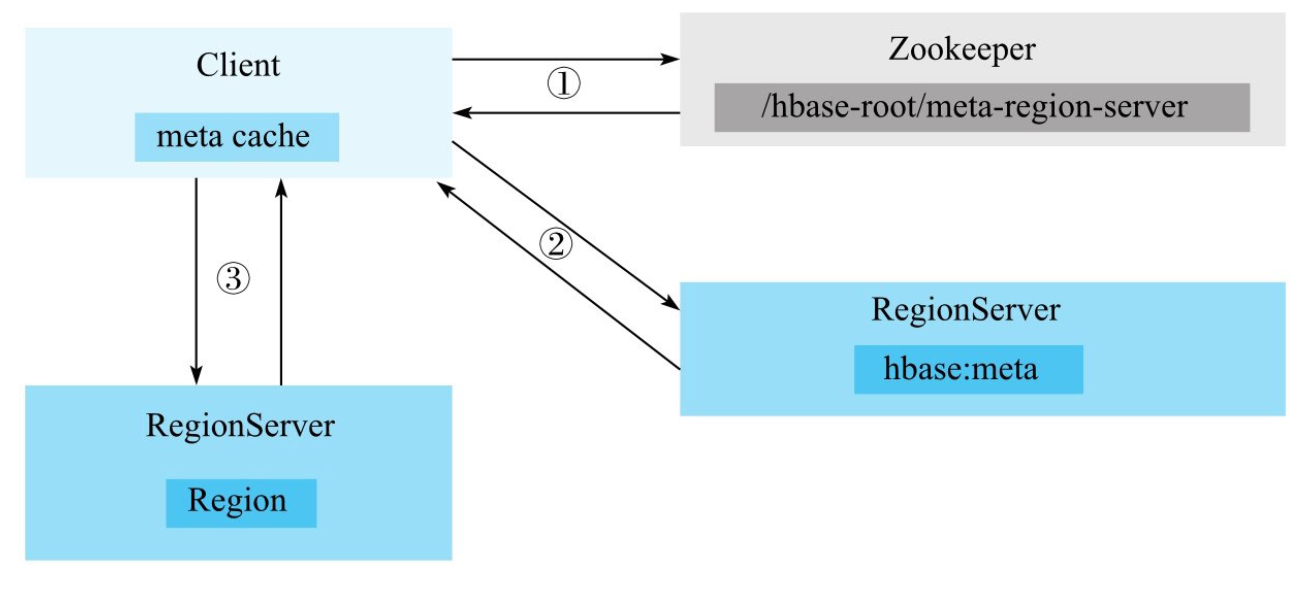
- 首先在meta cache 根据rowKey查找该rowKey对应的Region Server,如果有则直接发送请求到RegionServer。
- 如果客户端缓存中没有查到对应的rowkey信息,需要首先到ZooKeeper上/hbase-root/meta-region-server节点查找HBase元数据表所在的RegionServer。
- 向hbase:meta所在的RegionServer发送查询请求,在元数据表中查找rowkey所在的RegionServer以及Region信息,并缓存。
- 发送给目标RegionServer,Region Server接收到请求之后会解析出具体的Region信息,查到对应的Region对象,并将数据写入目标Region的MemStore中。
用户提交put请求后,HBase客户端会将写入的数据添加到本地缓冲区中,符合一定条件就会通过AsyncProcess异步批量提交。HBase默认设置autoflush=true,表示put请求直接会提交给服务器进行处理;用户可以设置autoflush=false,这样,put请求会首先放到本地缓冲区,等到本地缓冲区大小超过一定阈值(默认为2M,可以通过配置文件配置)之后才会提交。
2.Region写入
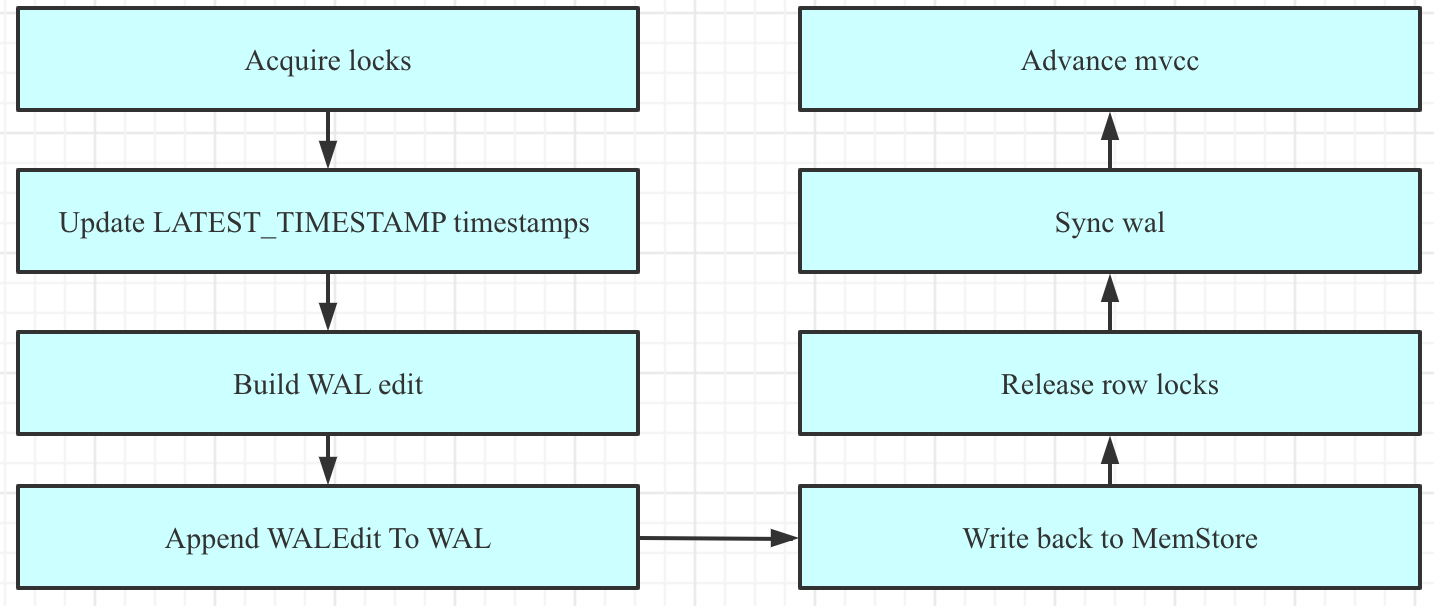
1)Acquire locks :HBase中使用行锁保证对同一行数据的更新都是互斥操作,用以保证更新的原子性,要么更新成功,要么更新失败。
2)Update LATEST_TIMESTAMP timestamps :更新所有待写入(更新)KeyValue的时间戳为当前系统时间。
3)Build WAL edit: 在内存中构建WALEdit对象,为了保证Region级别事务的写入原子性,一次写入操作中所有KeyValue会构建成一条WALEdit记录。
4)将WALEdit顺序写入Hlog中。
5)Write back to MemStore:写入WAL之后再将数据写入MemStore。
6)释放行锁。
7)Sync WAL: HLog真正sync到HDFS,在释放行锁之后执行sync操作是为了尽量减少持锁时间,提升写性能。如果sync失败,执行回滚操作将MemStore中已经写入的数据移除。
8)结束写事务。
3.MemStore Flush阶段
当MemStrore 的数据达到一定阈值,会flush
要掌握:
- MemStore Flush的触发时机
- MemStore Flush的整体流程
- HFile的构建流程
- HFile文件格式的构建
- 布隆过滤器的构建
- HFile索引的构建
- 元数据的构建
















本类排行
今日推荐






热门手游
-
方程式赛车公路赛车官方版

版本:1.0.1
大小:54.65MB
日期:2024-04-18
-
职业真车竞技场官方版

版本:1.0
大小:11.05MB
日期:2024-04-18
-
越野试验司机破解版

版本:0.1
大小:143.93MB
日期:2024-04-18
-
岛屿摩托骑士正式版

版本:0.5
大小:59.48MB
日期:2024-04-18
-
怪兽卡车挑战赛官方版

版本:1.0
大小:27.22MB
日期:2024-04-18
-
周五夜放克大蓝猫模组正式版

版本:2.0.2
大小:117.10MB
日期:2024-04-18