并发编程-ThreadLocal&ForkJoinPool(使用以及原理分析)
时间:2022-05-11 12:42
结果(每个线程获取的数据是一样的):我们其实可以用它存储用户信息,当前端传递过来一个token然后我们token进行解析,就可以当前用户信息存储在这个中。

如何应用在现实中(我们知道simpledatefromate不是线程安全的,那我们多个线程用同一个simpledatefromate一定会有问题,我们就可以用他来解决)
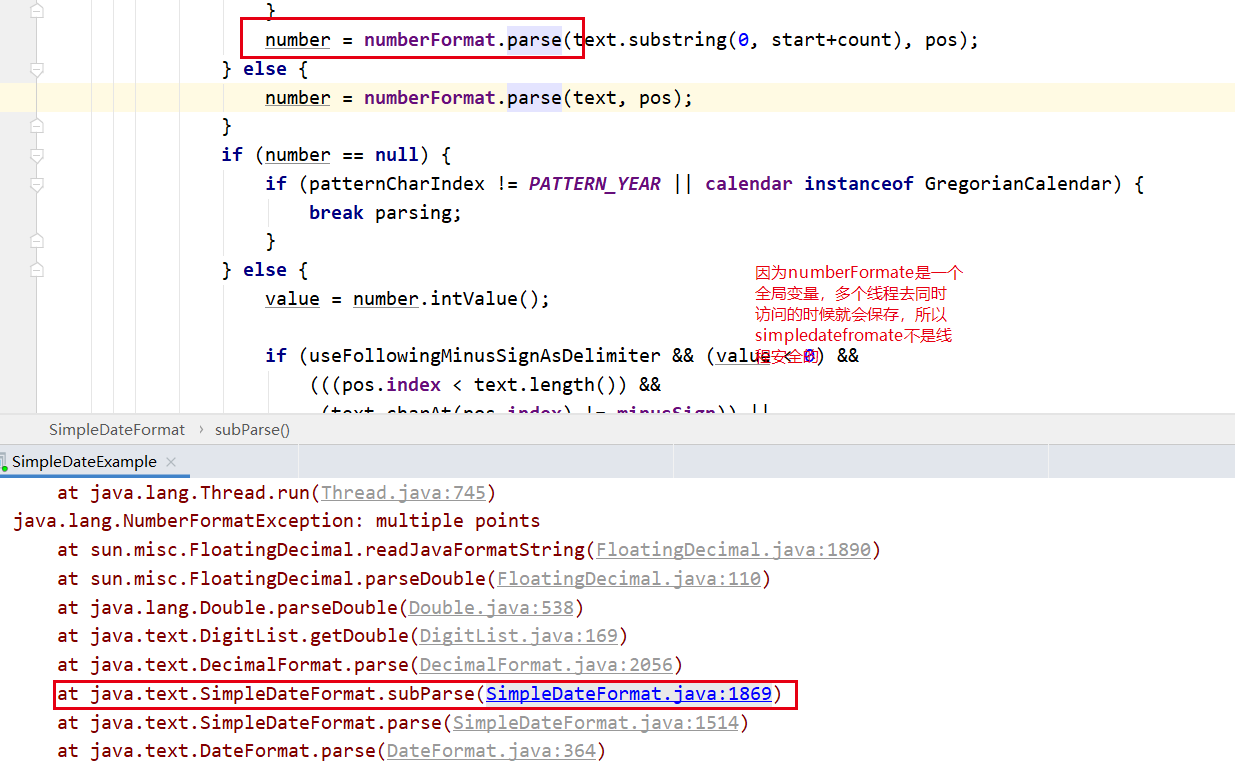
public class SimpleDateExample {
static ThreadLocal simpleDateFormatThreadLocal = new ThreadLocal<>();
static SimpleDateFormat getDateFormate() {
//从当前线程中获取
SimpleDateFormat simpleDateFormat = simpleDateFormatThreadLocal.get();
if (simpleDateFormat == null) {
// 在当前线程中设置一个
simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
simpleDateFormatThreadLocal.set(simpleDateFormat);
}
return simpleDateFormat;
}
private static Date parse(String strDate) throws ParseException {
return getDateFormate().parse(strDate);
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < 20; i++) {
executorService.execute(() -> {
try {
System.out.println(parse("1998-05-08"));
} catch (ParseException e) {
e.printStackTrace();
}
});
}
}
}
【原理】
主要有两个方法
- set:在当前线程中设置一个数,存储在ThreadLocal中,这个数值仅对当前线程可见【这就相当于在当前线程中建立了一个副本】
- get:从当前线程中取出set方法设置的数值
原理猜想:
- 能实现线程隔离,当前保存的线程只会存储在当前范围内
- 一定有一个容器存储这些副本,并且这个容器中的值肯定和每一个线程相关联
- 容器的key肯定和当前线程有关系,因为我们在get数据的时候没有传入任何key
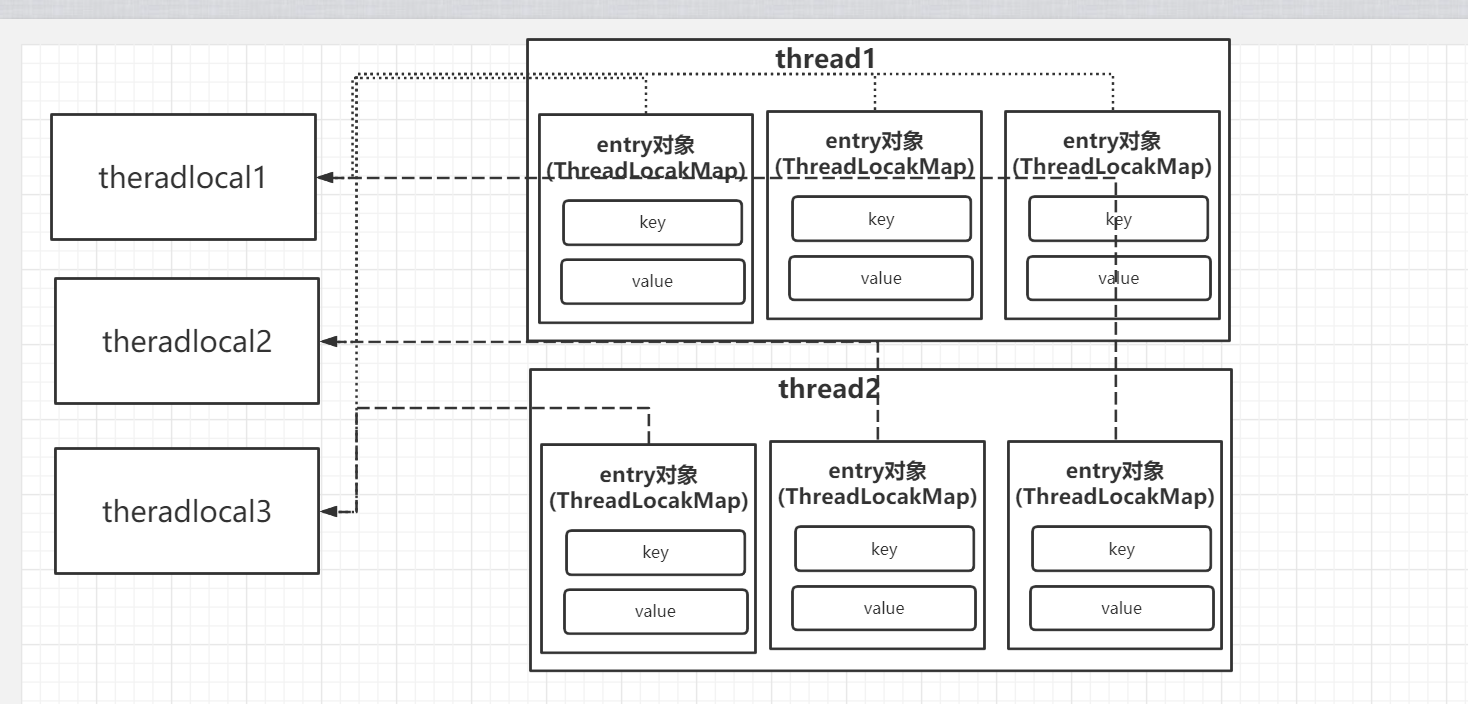
整体剖析(源码解析):其实是在每个线程中都把threadLoca存储在他当前的一个【ThreadLocalMap】中,key指向了ThreadLocalMap而value就是存储的数据
set():
public void set(T value) { Thread t = Thread.currentThread(); //根据当前线程获取ThreadLocalMap ThreadLocalMap map = getMap(t); if (map != null) //不为空则直接存储 map.set(this, value); else //初始化 createMap(t, value); }初始化
ThreadLocalMap(ThreadLocal firstKey, Object firstValue) { //默认长度为10 table = new Entry[INITIAL_CAPACITY]; //计算数组下标 int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); table[i] = new Entry(firstKey, firstValue); size = 1; setThreshold(INITIAL_CAPACITY); }存储数据
private void set(ThreadLocal key, Object value) { Entry[] tab = table; int len = tab.length; //根据key计算数组下标 int i = key.threadLocalHashCode & (len-1); //线性探索(这里是怕通过TheradLocal计算的数组下标是同一个,所以这里是解决hash冲突的) for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal k = e.get(); //如果这个位置有内容则直接进行替换 if (k == key) { e.value = value; return; } //如果key为空则证明这里存储的数据是一个脏数据,需要被清理(因为这里是弱引用,当threadLocal被Gc了那所引用他的对象也就为空了) if (k == null) {
//我们一会主要聊聊这个方法 replaceStaleEntry(key, value, i); return; } } tab[i] = new Entry(key, value); int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); }get()
public T get() { Thread t = Thread.currentThread(); // 获取当前线程的ThreadLocalMap ThreadLocalMap map = getMap(t); if (map != null) { //通过当前的ThreadLocal去获取数据 ThreadLocalMap.Entry e = map.getEntry(this); if (e != null) { @SuppressWarnings("unchecked") T result = (T)e.value; return result; } } return setInitialValue(); }private T setInitialValue() { //获取咱们设置的初始数据 T value = initialValue(); Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); return value; }在设置set内容的时候有一段代码比较特殊,我们来分析一下【replaceStaleEntry】:他主要做两件事情
【把当前的value存储在entry中】,【并且清理无效的key】但是里面牵扯到【线性寻址法】可以解决hash冲突,具体是这样的
从通过ThreadLocal生成的下标中向前查找,然后再向后查找。
【脏enrty】:指的是key为null
【可以替换的enrty】:传入的通过当前ThreadLocal计算的hash值和整个entry中的某个key相同,则把两个位置做一个替换
具体情况如下
- 向前查找到了脏的enrty(?),向后有可以替换的enrty(?)->这一步是最繁琐的,剩下的就简单啦
- 向前查找直到找到key为null结束然后使用【slotToExpunge】记住脏entry的下标
- 向后查找,假设我们要添加一个value为6的entry,我们换算出来的下标为4,向后查找,我们发现传入的key的hash值和下标是6的hash值是相同的,那我就互换他们的位置(如果不替换他们的位置,我们设置内容的时候就会存在冲突的问题)
- 这个时候从【slotToExpunge】这里还是给后面清理,从我们记住 的脏entry开始给后面遍历entry,把enrty中key为null的value设置为空
- 向前查找到了脏的enrty(?),向后没有发现可以替换的enrty(?)
- 这里就直接插入数据,因为没有hash冲突,然后我们向前查找,找到【slotToExpunge】,然后从这里再给遍历把key为null的value设置为空
- 向前查找没有脏的entry(?),向后发现了可以替换的enrty(?)
- 那就找到冲突的hash然后替换。
- 向前没有找到脏的enrty(?),向后没有发现可以替换的enrty(?)
- 那直接插入即可
- 如果当前下标对应的entry中的key为null,则向前查找是否还存在key为null的entry进行清理
- 通过线性探索解决hash冲突的问题
private void replaceStaleEntry(ThreadLocal key, Object value, int staleSlot) { Entry[] tab = table; int len = tab.length; Entry e; //这里定义了一个需要开始清理的位置 int slotToExpunge = staleSlot; //这里向前查找 for (int i = prevIndex(staleSlot, len); (e = tab[i]) != null; i = prevIndex(i, len)) //找到前面的key为null,然后记录开始查找位置 if (e.get() == null) slotToExpunge = i; //向下查找 for (int i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal k = e.get(); //如果找到一个相同的key if (k == key) { //这里就对他们进行替换 e.value = value; tab[i] = tab[staleSlot]; tab[staleSlot] = e; if (slotToExpunge == staleSlot) slotToExpunge = i; //这里清理无效的key cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); return; } if (k == null && slotToExpunge == staleSlot) slotToExpunge = i; } tab[staleSlot].value = null; tab[staleSlot] = new Entry(key, value); if (slotToExpunge != staleSlot) cleanSomeSlots(expungeStaleEntry(slotToExpunge), len); }对无效的key进行清理
//这里就是我们向前查到后找到的key为null的下标 private int expungeStaleEntry(int staleSlot) { Entry[] tab = table; int len = tab.length; tab[staleSlot].value = null; tab[staleSlot] = null; size--; Entry e; int i; //这里循环查找 for (i = nextIndex(staleSlot, len); (e = tab[i]) != null; i = nextIndex(i, len)) { ThreadLocal k = e.get(); //只要key为null,则设置他的value也为null if (k == null) { e.value = null; tab[i] = null; size--; } else { int h = k.threadLocalHashCode & (len - 1); if (h != i) { tab[i] = null; while (tab[h] != null) h = nextIndex(h, len); tab[h] = e; } } } return i; }关于内存泄漏问题,是会有极端情况下产生,你我们每次用完后就使用remove即可,remove底层也是使用了线性探索对key和value进行移除
Fork/Join
它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,有点像Hadoop
【使用】
API:
ForkJoinTask:
RecursiveAction:没有返回结果的
RecursiveTask:有返回结果的
CountedCompleter:没有返回值,但是任务触发后会进行回调
fork():让task异步执行
join():让task同步通同步,等待获得返回值
ForkJoinPool:专门用来运行ForkJoinTask的线程池
public class ForkJoinExample { //以200为一个单位进行拆分 private static Integer separateLine = 10; static class CalcJoinTask extends RecursiveTask{ //子任务开始计算的数值 private Integer startValue; //子任务开始结束计算的数值 private Integer endValue; CalcJoinTask(Integer startValue, Integer endValue) { this.startValue = startValue; this.endValue = endValue; } @Override protected Integer compute() { // 如果当前的数据计算已经小于给定数值则不需要进行拆分,否则会进行不断的拆分 if (endValue - startValue < separateLine) { System.out.println("开始计算startValue:" + startValue + "endValue:" + endValue); return endValue+startValue; } //从开始位置到一半的位置 CalcJoinTask calcJoinTask = new CalcJoinTask(startValue, (startValue + endValue) / 2); calcJoinTask.fork(); //总数一半加一的地方,到最大的数值 CalcJoinTask calcJoinTask1 = new CalcJoinTask((startValue + endValue) / 2 + 1, endValue); calcJoinTask1.fork(); //这里汇总总数 return calcJoinTask.join() + calcJoinTask1.join(); } } public static void main(String[] args) throws ExecutionException, InterruptedException { CalcJoinTask calcJoinTask = new CalcJoinTask(1, 100); ForkJoinPool forkJoinPool = new ForkJoinPool(); ForkJoinTask result = forkJoinPool.submit(calcJoinTask); System.out.println("result"+result.get()); } } 工作队列
我们看fork方法的底层是一个工作队列【workQueue】,他会把当前的任务放在一个workQueue,他是一个【双端队列】(是一个两端进行添加和操作元素的队列),他它可以实现后进先出(fifo),每个线程中都私有这样一个双端队列,这个队列中存储的就是fork添加进行去的任务,每次执行任务都从这个队列中取,因为是后进先出,所以第一个元素就是最后push进去的元素,执行完成第一个元素,把执行的数据传递给下一个队列中的元素。但是如果一个线程执行完成了他自己的任务,那怎么办,我们不能让他闲着,所有这里使用了一个工作窃取的算法
工作窃取
如果某个线程的【workQueue】执行完成了,那我先不闲着,我从其他的队列中去获取一个任务,从他们的对尾获取,这样就不会冲突,因为其他线程是从队头获取任务执行,这样就提升了性能
如何应用到实际业务中(拆分多个rpc任务去查询商品信息)
在一个电商系统中需要查询:商品信息查询(【RPC->】商品基本信息查询 & 商品评价信息查询) 店铺信息查询 (【RPC->】销售情况,店铺基本信息 )然后我们把每个查询都给他变成一个task
这里是所有的pojo类

















本类排行
今日推荐






热门手游
-
像素火影破解版

版本:v1.00.42
大小:222.66MB
日期:2024-05-18
-
谁先阵亡2完整版

版本:v1.0
大小:75.17MB
日期:2024-05-18
-
闪客连打明日英雄正式版

版本:v1.0
大小:65.31MB
日期:2024-05-18
-
七日重生正式版

版本:v2.6.2
大小:532.92MB
日期:2024-05-18
-
异形探索正式版

版本:v6.6.34
大小:160.63MB
日期:2024-05-18
-
3D超级保龄球大师官方版

版本:v1.1
大小:73.15MB
日期:2024-05-18