SQL存储原理及聚集索引、非聚集索引、唯一索引、主键约束的关系(补)
时间:2022-03-14 10:47
索引类型
1. 唯一索引:唯一索引不允许两行具有相同的索引值
2. 主键索引:为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的,并且不能为空
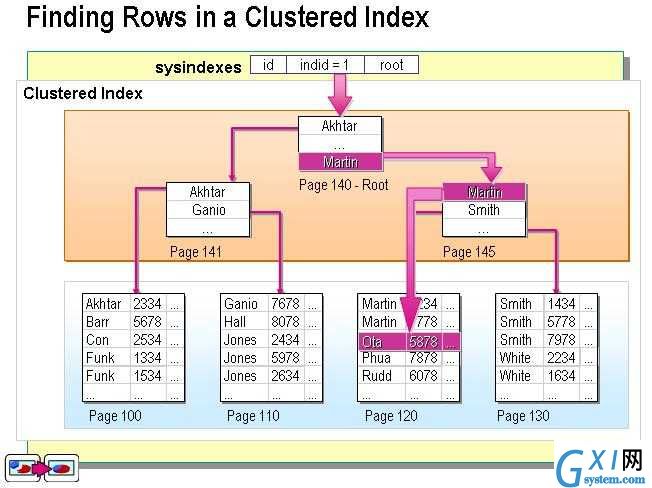
3. 聚集索引(Clustered):表中各行的物理顺序与键值的逻辑(索引)顺序相同,每个表只能有一个
4. 非聚集索引(Non-clustered):非聚集索引指定表的逻辑顺序。数据存储在一个位置,索引存储在另一个位置,索引中包含指向数据存储位置的指针。可以有多个,小于249个
聚集索引与非聚集索引,既可以是唯一索引也可以不是
主键索引是针对主键而言的,复合索引是针对多个列作为一个索引而言的,聚集索引并没有特殊之处,因为他仍然是使用一个列做索引,加一个唯一号码作为相同时的序号,索引有时候要避免使用复合索引。
唯一索引键可以为空,主键索引不可以。
对于大多数数据库引擎,创建主键会同时创建聚集索引,同时作为主键索引。
而创建一个唯一约束列,则会自动为该列创建唯一索引,该索引同时为非聚集索引。
自动创建的索引可删除,且
索引类型:再次用汉语字典打比方,希望大家能够明白聚集索引和非聚集索引这两个概念。
唯一索引:
唯一索引不允许两行具有相同的索引值。
如果现有数据中存在重复的键值,则大多数数据库都不允许将新创建的唯一索引与表一起保存。当新数据将使表中的键值重复时,数据库也拒绝接受此数据。例如,如果在stuInfo表中的学员员身份证号(stuID) 列上创建了唯一索引,则所有学员的身份证号不能重复。
提示:创建了唯一约束,将自动创建唯一索引。尽管唯一索引有助于找到信息,但为了获得最佳性能,建议使用主键约束或唯一约束。
主键索引:
在数据库关系图中为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的。当在查询中使用主键索引时,它还允许快速访问数据。
聚集索引(clustered index)
在聚集索引中,表中各行的物理顺序与键值的逻辑(索引)顺序相同。表只能包含一个聚集索引。例如:汉语字(词)典默认按拼音排序编排字典中的每页页码。拼音字母a,b,c,d……x,y,z就是索引的逻辑顺序,而页码1,2,3……就是物理顺序。默认按拼音排序的字典,其索引顺序和逻辑顺序是一致的。即拼音顺序较后的字(词)对应的页码也较大。如拼音“ha”对应的字(词)页码就比拼音“ba” 对应的字(词)页码靠后。
非聚集索引(Non-clustered)
如果不是聚集索引,表中各行的物理顺序与键值的逻辑顺序不匹配。聚集索引比非聚集索引(nonclustered index)有更快的数据访问速度。例如,按笔画排序的索引就是非聚集索引,“1”画的字(词)对应的页码可能比“3”画的字(词)对应的页码大(靠后)。
提示:SQL Server中,一个表只能创建1个聚集索引,多个非聚集索引。设置某列为主键,该列就默认为聚集索引
对于Oracle数据库:
我们指定了ID列作为主键,Oracle数据库会自动创建一个同名的唯一索引
那么唯一键约束的情况是怎样的呢?Oracle同样自动创建了一个同名的唯一索引,而且也不允许再在此列上创建唯一索引或非唯一索引。
唯一键约束并没有非空要求。
唯一索引与唯一键约束一样对列值非空不做要求。
如果我们让主键约束或者唯一键约束失效,Oracle自动创建的唯一索引是否会受到影响?当主键约束或者唯一键约束失效时,Oracle会标记隐式创建的唯一索引为删除状态。
如果我们先创建唯一索引,再创建主键或者唯一键约束,情况又会怎样呢?实验结果表明,先创建的唯一索引不受约束失效的影响。
总结如下: (1)主键约束和唯一键约束均会隐式创建同名的唯一索引,当主键约束或者唯一键约束失效时,隐式创建的唯一索引会被删除; (2)主键约束要求列值非空,而唯一键约束和唯一索引不要求列值非空; (3)相同字段序列不允许重复创建索引; 同样的图: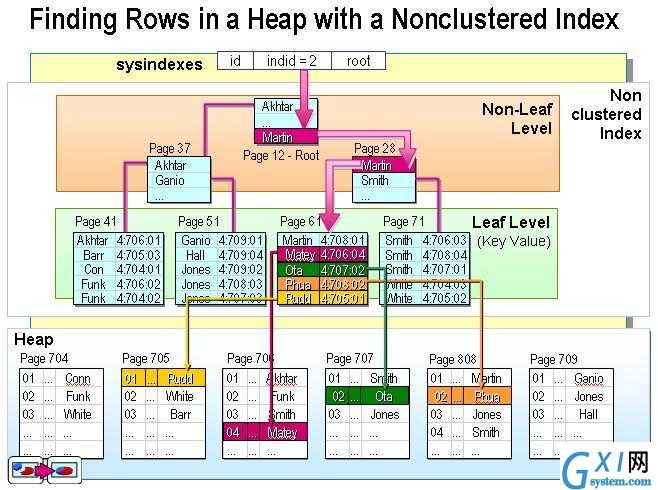
 关于区:
关于区:
前面的文章我介绍了数据文件中的页,包括页结构和一些页类型。现在我想解释一下页是如何组织成区( extent )的。一个区是由数据文件中 8 个连续的页组成。区从数据文件头部开始,并且总是 64K 对齐(即: 8 页对齐)。区及其属性在 SQL SERVER 2000 和 2005 中是一模一样的。
SQL SERVER 中有两种类型的区:混合区和统一区。
混合区
分配给任意一条 IAM 链( SQL SERVER 2000 中的一个索引或者是 2005 中的分配单元)的前 8 个页的分配单位是单个页,这种页被称为混合页。就是说每次分配的是一个单独的页而不是一个区。这样便允许非常小的表花费最小数量的空间。一旦一条 IAM 链跨过了前 8 页的门槛,以后便分配统一区,再也不会分配混合页了。
从混合区中分配来的混合页,不需要分配给特定的 IAM 链。因为这些区会被全局分配跟踪(通过 GAM 页),所以不会分配给一个 IAM 链的。混合区中若还有没分配的页,该区同时会被 SGAM 页跟踪。当需要分配一个混合页,系统就会检查 SGAM 页是否还有这样的区。如果没有的话,就会分配一个新的混合区,并从中分配一页,然后这个区就被 SGAM 页跟踪直到所有的页被分配。
因为混合区不会被分配给一个特定的 IAM 链,这就是说它可能分配给 8 个不同的 IAM 链。不管有多少页被分配给 IAM 链, IAM 页本身总是混合页。这就是说一个混合区可有多种页类型,包括 IAM 页、数据页、索引页或文本页。
统一区
一旦跨过了 8 页的门槛,以后就从统一区上分配给 IAM 链了。这就是说一次分配一个区给一条 IAM 链,并在 IAM 链上的 IAM 页上标明——不管是谁映射该区所在的 GAM 区间的。该区同时会被相关的的 GAM 页跟踪是否已分配,这样其它的 IAM 链就不会再分配它了。
一个统一区的所有页必须分给同一条 IAM 链。然后,它们不需要是同一类型的页。比如,一个聚集索引会同时有数据和索引页。当一个区被分配给 IAM链时,该区中的页并不是一次全被分配掉的(除非是大型数据操作),这些页通常是按需分配,每页的分配情况有 PFS 页跟踪。
当一个统一区的所有页都被释放,那么区本身就从拥有它的 IAM 链中释放了,并且可以再次分配给其他的 IAM 链,或者成为混合区。
为备份跟踪变化的区
系统中有两个地方用来跟踪变化的区:
1. 自上次完整备份以来所有改变的区会有相关的差异位图页( differential bitmap page )跟踪。这样差异备份时便可以知道哪些区需要备份而不是备份整个数据库了。当下次完整备份时所有的差异位图页都被复位。
2. 自上次完整、差异或日志备份以来一个区在 BULK-LOGGED 恢复模式下发生了大日志操作,会有相关的最小日志位图页( minimally-logged bitmap page )跟踪。大日志操作后的任何日志备份就会包含所有这些跟踪的区。当下次备份时,所有的最小日志位图页都会被复位。
这里是所有类型的原理及作用:http://blog.csdn.net/misterliwei/article/details/5939524
还有从这里取得内容:http://www.cnblogs.com/lyhabc/p/3196479.html
这是一个典型的聚集索引表的分页情况
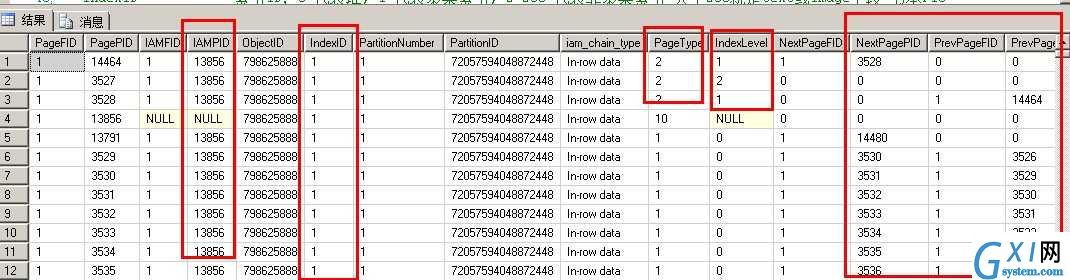
红色框部分都是需要关注的
PageType 分页类型: 1:数据页面;2:索引页面;3:Lob_mixed_page;4:Lob_tree_page;10:IAM页面
IndexID 索引ID: 0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引 ,大于250就是text或image字段
对于聚集索引:
第二个:每个数据页的IndexID都是1,不是说数据页变成了索引页,而是说现在数据页已经属于聚集索引的一部分,不在堆里了
第三个:每个数据页的IndexLevel都是0,就是说数据页在聚集索引的最下层
IndexLevel指B树层次,最下层为0,上层依次递增。
FID为fileID或者分区ID,PID为pageID,1:13856指的就是1区13856PID的位置,最后还可以有一个行值1:13856:2第二行的意思。
IAMPID为物理上的顺序ID,而PagePID为逻辑上的顺序ID。0指null,即没有。
















本类排行
今日推荐
-
英语单词宝新版

版本:v1.1
大小:24.5M
日期:2024-04-20
-
云数字园区新版

版本:v5.17.0
大小:118.9M
日期:2024-04-20
-
驹卒智外勤官方版

版本:v1.0.0
大小:17.0M
日期:2024-04-20
-
PDF格式转换器正式版

版本:v1.0.0
大小:20.8M
日期:2024-04-20
-
钢琴节奏键盘大师完整版

版本:v1.5.2.1
大小:50.2M
日期:2024-04-20
-
百咔相机免费版

版本:1.00
大小:83.16MB
日期:2024-04-20
热门手游
-
狙击任务官方版

版本:v1.3.4
大小:158.6M
日期:2024-04-19
-
僵尸大战3d官方版

版本:v2.6.8
大小:105.1M
日期:2024-04-19
-
塞拉七号全武器解锁无限金币版

版本:v0.0.318
大小:98.3M
日期:2024-04-19
-
子弹力量内置作弊菜单版

版本:v1.90.0
大小:457.9M
日期:2024-04-19
-
我会活下去新版

版本:v1.0
大小:124.9M
日期:2024-04-19
-
周五夜放克破解版

版本:0.2.7
大小:173.99MB
日期:2024-04-19