MongoDB 进阶-关联查询
时间:2022-03-13 23:57
【苏州需要工作的加我QQ,内推介绍费平分】
1.数据库命令
a.命令的工作原理
drop命令,在shell中删除一个集合,执行db.refactor.drop().其实这个函数实际运行的是drop命令,
可以用runCommand来达到一样的效果:
db.runCommand({"drop":"refactor"})
{ "nIndexesWas" : 1, "msg" : "indexes dropped for collection", "ns" : "test.refactor", "ok" : 1 } 命令的响应是一个文档,包含了命令是否执行成功,还可能有些其他的命令输出的信息.命令的响应文档
都有一个"ok"键.ok键的值为1表示执行成功,为0表示执行失败,当为0时,会有一个"errmsg"键,
它的值表示命令失败的原因.
MongoDB中的命令其实是作为一种特殊类型的查询实现的,这些查询针对$cmd集合来执行.runCommand
仅仅是接受命令文档,执行等价查询,因此drop调用实际上是这样的:
db.$cmd.findOne({"drop":"refactor"})
当MongoDB服务器得到查询$cmd集合的请求时,会启动一套特殊的逻辑来处理,而不是交给普通的查询代码来执行.
几乎所有MongoDB驱动程序都提供一个类似runCommand的帮助方法来执行命令,如果有必要,也可以使用一个
简单查询的方式来运行命令.
访问有些命令需要有管理员权限,必须在admin数据库里面运行.
b)要获得所有命令的最新列表,可以在shell中运行db.listCommands(),
也可以使用http://localhost:28017/_commands
2.固定集合
MongoDB不仅支持普通集合,还支持 固定集合,固定集合要事先创建,而且大小固定.
固定集合像一个环形队列,如果空间不足,最早的文档就会被删除,为新的文档提供空间.
固定集合在新文档插入的时候自动淘汰最早的文档.
固定集合不能删除文档(自动淘汰文档除外),更新(尺寸增大)将导致文档移动.
固定集合中的文档以插入的顺序存储,不用维护一个已删除的文档释放空间列表.
固定集合默认情况下没有索引,即便是"_id"上也没有索引.
a.固定集合的属性和用法
对固定集合插入的速度很快,做插入操作时,无需额外分配空间,服务器也不必查找空闲列表来放置文档,
直接将文档插入集合的末尾就行了,如果有必要就将旧的覆盖.默认情况下插入也无需更新索引.
对固定集合按照插入顺序输出的查询速度很快,以为文档本身就是按照插入顺序存储的,按照这个
顺序查询就是遍历一下,返回结果的顺序就是文档在磁盘上的顺序.默认情况下,对固定集合进行查找都
会以插入的顺序返回结果.
固定集合能在新数据插入时,自动淘汰最早的数据.插入快速,按照插入顺序查询也很快,自动淘汰,这几个
属性组合起来使得固定集合特别适合像日志这种应用场景.事实上,MongoDB中设计固定集合的目的
就是用来存储内部的复制日志oplog.固定集合还有一个用法是缓存少量的文档,一般来说,固定集合
使用与任何想要自动淘汰过期属性的场景.
b.创建固定集合
固定集合必须要在使用前显示的创建.
如:
db.createCollection("refactorCapped",{"capped":true,size:100000,max:100})
上面的命令创建了一个固定集合refactorCapped,大小是100000字节,最大的文档数100.
当指定文档数量的上限时,必须同时指定大小.淘汰机制只有在容量还没有满时才会依据文档数量来工作.
要是容量满了,淘汰机制则会依据容量来工作.
可以将普通集合转化成固定集合,如将blog集合转换成大小为10000字节的固定集合
db.runCommand({convertToCapped:"blog",size:10000})
c.自然排序
固定集合的排序方式叫做自然排序.自然排序就是文档在磁盘上的顺序.
因为固定集合的文档总是按照插入的顺序存储的,自然顺序就是这样的.默认情况下,
查询固定集合后就是按照插入的顺序返回文档.也可以使用自然排序按照反向插入的顺序查询
如
db.blog.find().sort({"$natural":-1})
3.GridFS
GridFS是一种在MongoDB中存储大二进制文件的机制,使用GridFS存文件的原因:
GridFS可以直接利用已经建立的复制或分片机制,对文件存储来说故障恢复和扩展都很容易
GridFS可以避免用于存储用户上传内容的文件系统出现的某些问题,如GridFS在同一个目录下放置大量的文件是没有问题的.
GridFS不产生磁盘碎片,因为MongoDB分配数据文件空间时以2GB为一块.
a.使用GridFS
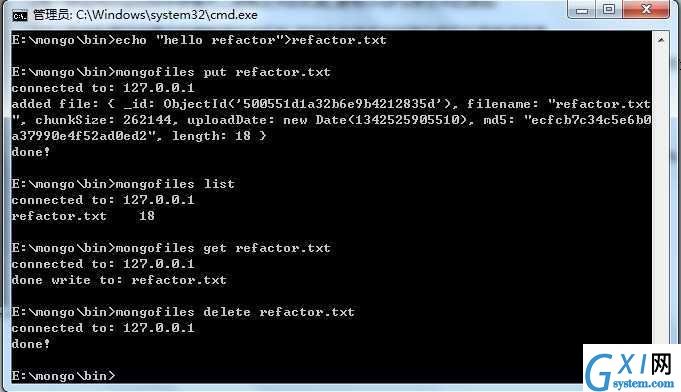
最简单使用GridFS的方法是利用mongofiles.mongofiles可以用来在GridFS中上传,下载,列示,查找和删除文件.
可以用 mongofiles --help获得帮助
如:
b)内部原理
GridFS是一个建立在普通MongoDB文档基础上的轻量级文件存储规范.MongoDB服务器实际上对GridFS请求和普通的
请求一样,所有相关工作都由客户端驱动或者工具来完成.
GridFS的基本思想是可以将大文件分成很多块,每块作为一个单独的文档存储,这样就能存储大文件了.由于MongoDB
支持在文档中存储二进制数据,可以最大限度减小块的存储开销.另外,除了存储文件本身的快,还有一个单独的文档用来
存储分块的信息和文件的元数据.
GridFS的块有个单独的集合,默认情况下,块将使用fs.chunks集合,如果需要可以覆盖.这个块集合里面文档的结构很简单
{
"_id":ObjectId("...."),
"n":0,
"data":BindData("..."),
"files_id":ObjectId("....")
}
和别的MongoDB文档一样,块也有自己唯一的"_id".files_id键是包含这个块元数据的文件文档的"_id".
n表示块编号,也就是这个块在源文件中的顺序编号,data包含组成文件块的二进制数据.
文件的元数据放在另一个集合中,默认是fs.files.这里面的每个文档代表GridFS中的一个文件,与文件相关的
自定义元数据也可以存在其中.除了用户自定义的键,GridFS规范定义了一些键
_id
文件唯一的id,在块中作为files_id键的值存储
length
文件内容总的字节数
chunksize
每块的大小,以字节为单位,默认是256k,必要时可以调整.
uploadDate
文件存入GridFS的时间戳
md5
文件内容的md5检验和,由服务端用filemd5命令生成的,用于计算上传块的md5检验和
也意味着用户可以检验md5键这个值,确保文件正确上传了.
db.fs.files.find()
4.服务器端脚本
在服务器端可以通过db.eval函数来执行javascript脚本,也可以把javascript脚本保存在数据库中,然后
在别的数据库命令中调用.
a. db.eval
利用db.eval函数可以在MongoDB服务器端执行javascript脚本.这个函数先将给定的javascript字符串传递给
MongoDB服务器,在服务器上执行,然后返回结果.
db.eval可以用来模拟多文档事务:db.eval锁住数据库,然后执行javascript,再解锁.虽然没有内置的回滚机制,
但这能确保一系列操作按照指定的数序发生.
发送代码有两种方式,封装一个函数或者不封装,如:
db.eval("return ‘refactor‘;") db.eval("function(){return ‘refactor‘;}")
只有传递参数的时候,才必须要封装成一个函数.参数通过db.eval的第二个参数传递,要写成一个数组的形式.
如:
db.eval("function(name){return ‘hello,‘+name;}",[‘refactor‘])
若db.eval的表达式要是复杂的话,调试的办法是将调试信息写进数据库的日志中
如:
db.eval("print(‘hello refactor‘)")
这样在日志里就能找到hello refactor
b.存储javascript
每个MongoDB的数据库中都有个特殊的集合:system.js,用来存放javascript变量.这些变量可以在任何MongoDB的
javascript上下文中调用,包括"$where"子句,db.eval调用,MapReduce作业.用insert可以将变量存在system.js中
如:
db.system.js.insert({"_id":"x","value":1}) db.system.js.insert({"_id":"y","value":2}) db.system.js.insert({"_id":"z","value":3})
上例在全局作用域中定义了x,y,z,对其求和: db.eval("return x+y+z;")
system.js可以存放javascript代码,这样就可以很方便的自定义一些脚本,如用javascript写一个日志函数,将其存放在
system.js中:
db.system.js.insert( { "_id":"log", "value":function(msg,level) { var levels=["DEBUG","WARN","ERROR","PATAL"]; level=level?level:0; var now= new Date(); print( now +" "+ levels[level]+msg); } } )
调用:
db.eval("log(‘refactor bolg test‘,1)")
使用存储的javascript缺点是代码会与常规的源代码控制脱离,会弄乱客户端发送来的javascript.
最适合使用存储javascript的情况就是程序中有个地方都要用到一个javascript函数,这样要是更新的话,
只需更新这个函数而不必没出都修改.要是javascript代码很长又要繁琐使用的话,也可以使用存储javascript,
这样村一次会节省不少王扩传输时间.
c.安全性
执行javascript代码就要考虑MongoDB的安全性.
如:
>func="function(){print(‘hello,"+username+"!‘);}"
如果username是用户自定义的,可以使用这样的字符串"‘);db.dropDatabase();print(‘",
代码就变成了这样:
>func="function(){print(‘hello,‘);db.dropDatabase();print(‘!‘);}"
为了避免这种情况,要限定作用域.
绝大多数驱动程序都为传递给数据库的代码提供了一种特殊类型,这是因为代码实际上可以看成是一个字符串和一个
作用域的组合.作用域是一个保存着变量名和值映射关系的文档.当javascript函数执行的时候,这种映射就
构成了函数的局部作用域.
5.数据库引用
DBRef就像url,唯一确定一个到文档的引用.它自动加载文档的方式就像网站中url通过链接自动加载web页面一样.
a.DBRef是什么
DBRef是一个内嵌文档,DBRef有些必选键,如:
{"$ref":collectionName,"$id":id_value}
DBRef指向一个集合,还有一个id_value用来在集合里面根据"_id"确定唯一的文档.这两条信息可以使DBRef能
唯一标识MongoDB数据库内的任何一个文档.如想引用另一个数据库的文档,DBRef中有可选键"$db"
{"$ref":collectionName,"$id":id_value,"$db":database}//注意键的顺序不能改变.
b.实例
两个集合 users(用户),notes(笔记),
用户可以创建笔记,笔记可以引用用户或者别的笔记.
db.users.insert({"_id":"refactor","displayName":"dis_refactor"}) db.users.insert({"_id":"refactor2","displayName":"dis_refactor2"})
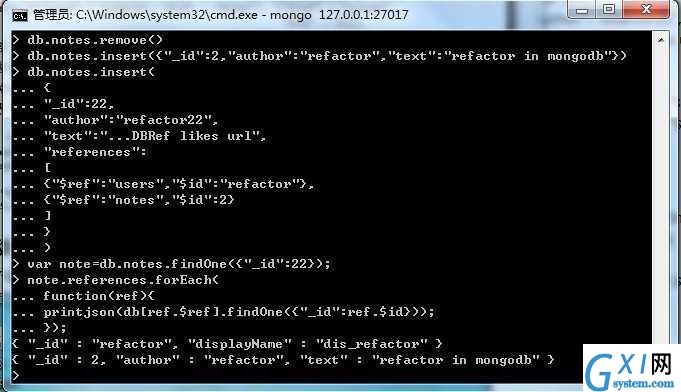
db.notes.insert({"_id":2,"author":"refactor","text":"refactor in mongodb"}) db.notes.insert( { "_id":22, "author":"refactor22", "text":"...DBRef likes url", "references": [ {"$ref":"users","$id":"refactor"}, {"$ref":"notes","$id":2} ] } )
var note=db.notes.findOne({"_id":22}); note.references.forEach( function(ref){ printjson(db[ref.$ref].findOne({"_id":ref.$id})); });
c.什么时候使用DBRef
在MongoDB中表示这种对其他文档的引用关系,并不是只有DBRef方式.
上面的例子就用了另外一种引用:每个note的author键仅存储了author文档的"_id"键,没有必要用DBRef,因为已经
知道每个author就是users集合里面的一个文档.这种引用在GridFS的块文档中"files_id"键仅仅就是对文档"_id"的引用.
在保存引用的时候是选择DBRef还是至存储"_id"?
保存"_id"会更加紧凑,对开发者而言就很轻量.但是DBRef能够引用任意集合(甚至是任意数据库)的文档,开发者
不必知道和记住被引用的文档在哪些集合里面.驱动程序和一些工具对DBRef提供了额外的功能(如自动去引用).
总之,存储一些对 不同 集合的 文档的引用时,最好用DBRef.否则最好存储"_id"作为引用来使用,这样更简单,也更容易操作.
















本类排行
今日推荐






热门手游
-
孤塔防御正式版

版本:v1.0.46
大小:34.85MB
日期:2024-05-08
-
英雄塔战官方版

版本:v0.14.1
大小:65.44MB
日期:2024-05-08
-
星骸骑士正式版

版本:v1.0.9
大小:1623.76MB
日期:2024-05-08
-
梦想农场官方版

版本:v1.0.1
大小:133.84MB
日期:2024-05-08
-
JUMP群星集结正式版

版本:v1.1.0
大小:949.31MB
日期:2024-05-08
-
我在神界刷装备永久免费版

版本:v52.0
大小:115.25MB
日期:2024-05-08