MYSQL 索引(二)--- 索引优化
时间:2022-03-16 12:02

索引单表调优案例
CREATE TABLE IF NOT EXISTS `article`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`author_id` INT(10) UNSIGNED NOT NULL,
`category_id` INT(10) UNSIGNED NOT NULL,
`views` INT(10) UNSIGNED NOT NULL,
`comments` INT(10) UNSIGNED NOT NULL,
`title` VARBINARY(255) NOT NULL,
`content` TEXT NOT NULL
);
INSERT INTO `article` (`author_id`,`category_id`,`views`,`comments`,`title`,`content`) VALUES(1, 1, 1, 1, ‘1‘, ‘1‘),
(2, 2, 2, 2, ‘2‘, ‘2‘),
(1, 1, 3, 3, ‘3‘, ‘3‘);
select * from article;
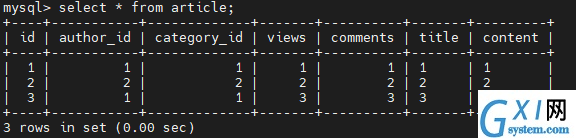
目标
查询 category_id 为 1,且 comments 大于 1的情况下, views 最多的 article_id。
SELECT id,author_id from article WHERE category_id =1 AND comments > 1 ORDER BY views DESC LIMIT 1;
EXPLAIN SELECT id,author_id from article WHERE category_id =1 AND comments > 1 ORDER BY views DESC LIMIT 1;
show index from article;
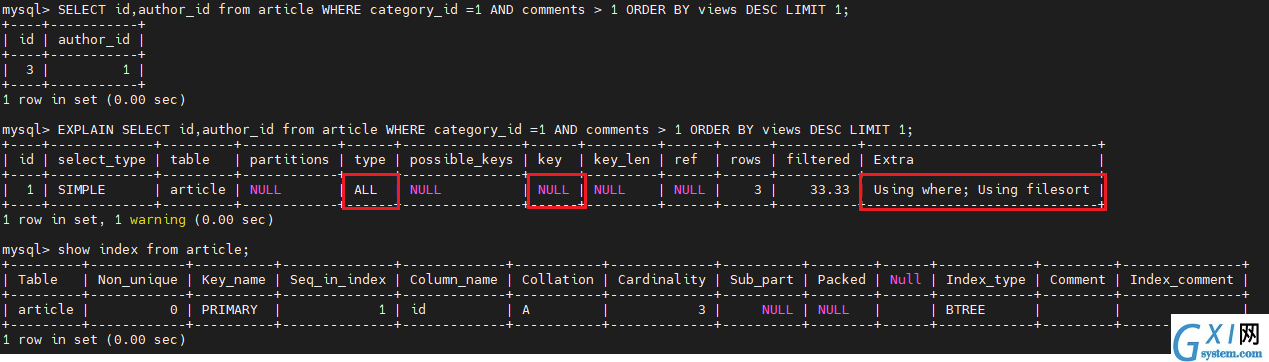
第一轮调优
type 是 ALL,即最坏的情况。Extra中还出现了Using filesort,也是最坏的情况。优化是必须的。
# 新建索引
create index idx_article_ccv on article(category_id,comments,views);
# 或者
# ALTER TABLE ‘article‘ ADD INDEX idx_article_ccv (`category_id`,`comments`,`view`);
show index from article;
EXPLAIN SELECT id,author_id from article WHERE category_id =1 AND comments > 1 ORDER BY views DESC LIMIT 1;
EXPLAIN SELECT id,author_id from article WHERE category_id =1 AND comments = 1 ORDER BY views DESC LIMIT 1;
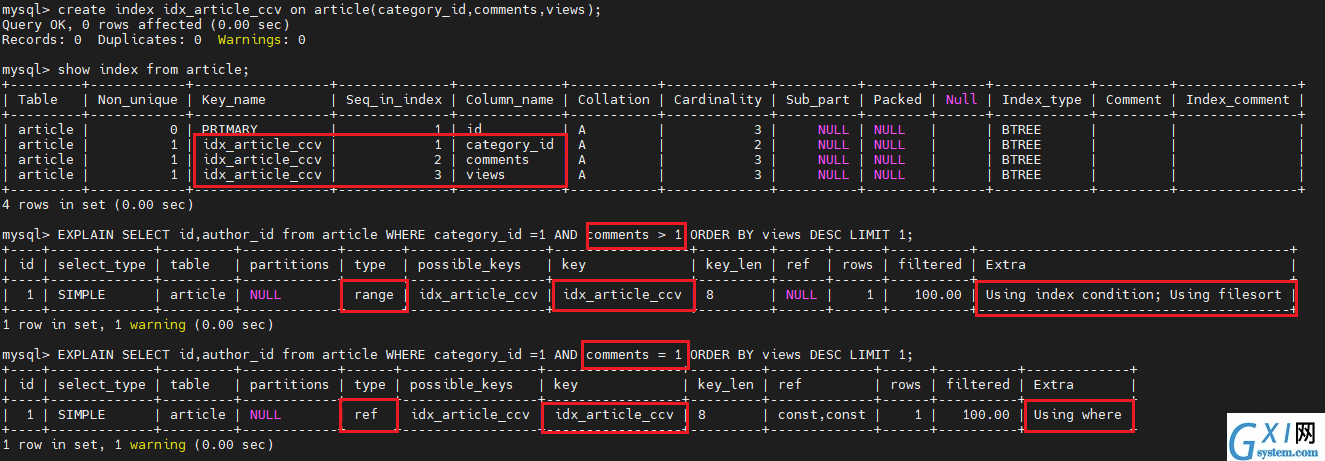
第二轮调优
type 变成了 range,这是可以接受的。但是 extra 里使用 using filesort 还是无法接受的。
我们已经建立了索引,为什么没用呢?
按照 BTree 树索引的工作原理,先排序 category_id,再排序 comments,如果遇到相同的 comments 再排序 views。当 comments 子段在联合索引中处于中间位置时,因为 comments>1 条件是一个范围值(range),Mysql无法利用索引再对后面的 views 部分进行检索,即 range 类型查询字段后面的索引无效。
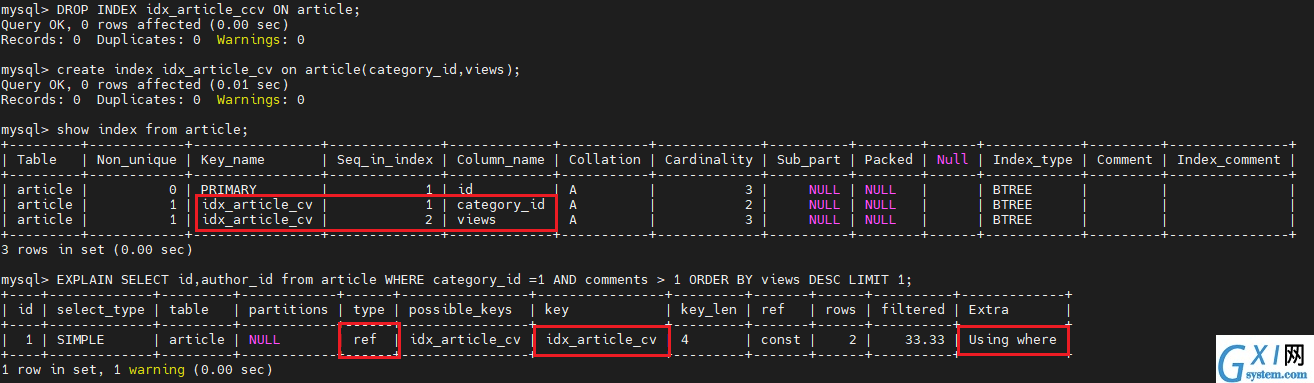
DROP INDEX idx_article_ccv ON article;
create index idx_article_cv on article(category_id,views);
show index from article;
EXPLAIN SELECT id,author_id from article WHERE category_id =1 AND comments > 1 ORDER BY views DESC LIMIT 1;
索引两表调优案例
CREATE TABLE IF NOT EXISTS `class`(
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE IF NOT EXISTS `book`(
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
INSERT INTO class (card) VALUES(FLOOR(1+(RAND()*20)));
... #20 条 RAND() 随机数
INSERT INTO class (card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book (card) VALUES(FLOOR(1+(RAND()*20)));
... #20 条
INSERT INTO book (card) VALUES(FLOOR(1+(RAND()*20)));
目标
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

type为 ALL,需要优化。
第一轮优化
ALTER TABLE `book` ADD INDEX Y (`card`);
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

第二轮优化
DROP INDEX Y ON book;
ALTER TABLE `class` ADD INDEX Y (`card`);
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

结论
第一次优化中 type 变为 ref,rows 变成了 2,优化比较明显。但是第二轮优化中并没有提升。
这是由左连接特性决定了, LEFT JOIN 条件用于确定如何从右表搜索行,左表一定都有。所以右表建索引才有效。
同理,右连接一样。RIGHT JOIN 条件用于确定如何从左表搜索行,右表一定都有。所以左表建索引才有效。
三表优化
CREATE TABLE IF NOT EXISTS `phone`(
`phoneid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`phoneid`)
);
INSERT INTO phone (card) VALUES(FLOOR(1+(RAND()*20)));
... #20 条 RAND() 随机数
INSERT INTO phone (card) VALUES(FLOOR(1+(RAND()*20)));
目标
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone on book.card = phone.card;

第一轮优化
ALTER TABLE `book` ADD INDEX Y (`card`);
ALTER TABLE `phone` ADD INDEX Z (`card`);
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone on book.card = phone.card;

后两行的type 都是 ref,并且 rows 优化效果也很好。因此索引最好设置在需要经常查询的字段中。
JOIN语句的优化
- 尽可能减少 JOIN 语句中 NestedLoop 的循环总次数:“永远用小结果集驱动大的结果集”
- 优先优化 NestedLoop 的内层循环
- 保证 JOIN 语句中被驱动表上 JOIN 条件字段已经被索引
- 当无法保证被驱动表的JOIN条件字段被索引且内存资源充足的情况下,不要太吝惜 JOINBUFFER 设置
索引优化
索引注意点
- 全值匹配最好
- 最佳左前缀法则:如果索引了多列,查询从索引的最左前列开始并且不跳过索引中的列
- 不在索引列上做任何操作(计算,函数,类型转换),会导致索引失效而转向全表扫描
- 存储引擎不能使用索引中范围条件右边的列
- 尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少 select *
- mysql 在使用 不等于 ( != or <>) 时无法使用索引会导致全表扫描
- is null, is not nuill 无法使用索引
- like 以通配符开头会使索引失效变为全表扫描(必须使用通配符开头可以使用覆盖索引)
- 字符串不加单引号索引失效
- 少用 or,用 or 连接时会导致索引失效
建议
- 对于单建索引,尽量选择针对当前 query 过滤性更好地索引
- 在选择组合索引时,当前 Query 中过滤性最好的字段在索引子弹顺序中,子弹越靠前越好
- 在选择组合索引时,尽量选择可以能够包含当前 query 中的 where 子句中更多字段的索引
- 尽可能通过分析统计信息和调整 query 的写法来达到选择适合索引的目的
查询优化
小表驱动大表
select * from A where id in (select id from B)
等价于
for select id from B
for select * from A where A.id=B.id
当 B 表的数据集小于 A 表的数据集时,用 in 优于 exists
select * from A where exists (select id from B where B.id = A.id)
等价于
for select * from A
for select * from B where A.id=B.id
当 A 表的数据集小于 B 表的数据集时,用 exists 优于 in
- EXISTS
可以理解为:将主查询的数据放在子查询中做条件验证,根据验证结果来决定主数据的数据结果是否可以保留- EXISTS(query) 只会返回 TRUE 或 FALSE,因此子查询中的 SELECT * 等,官方说法实际执行时会忽略 SELECT 清单
- EXISTS 子查询的实际执行过程可能经过了优化而不是逐条对比
- EXISTS 也可以使用条件表达式·其他子查询或者 JOIN 来替代,根据具体情况分析
Order By
CREATE TABLE tblA(
age INT,
birth TIMESTAMP NOT NULL
);
INSERT INTO tblA(age,birth) VALUES(22,NOW());
INSERT INTO tblA(age,birth) VALUES(22,NOW());
INSERT INTO tblA(age,birth) VALUES(22,NOW());
CREATE INDEX idx_A_ageBirth on tblA(age,birth);
SELECT * FROM tblA;
EXPLAIN SELECT * FROM tblA WHERE age>20 order by age;
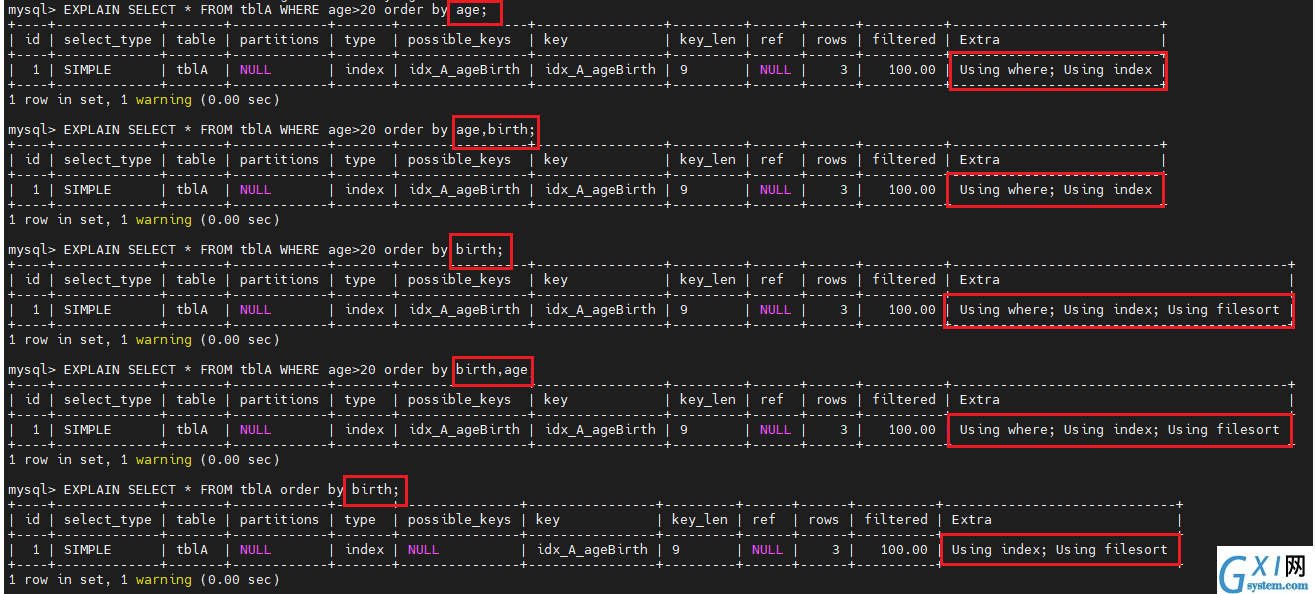

SQL 支持两种方式的排序,FileSort 和 Index,Index 效率高。
ORDER BY 满足两种情况会使用 Index 排序:
- ORDER BY 语句使用索引最左前列
- 使用 WHERE 子句与 ORDER BY 子句条件组合满足索引最左前列
所以尽可能在索引列上完成排序,遵照索引的最佳左前缀。
如果不在索引列上,filesort 有两种算法:
- 双路排序: MYSQL 4.1 之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据。
读取行指针和orderby 列,对他们进行排序,然后扫描已经排好序的列表,按照列表中的值重新从列表中读取对应的数据输出 - 单路排序: 从磁盘读取查询需要的所有列,按照 order by列在 buffer 对他们进行排序,然后搜啊买哦排序后的列表进行输出。效率更快,避免的第二次读取数据,并且把随机IO变成了顺序IO,但是由于它把每一行都保存在内存中了,所以会使用更多的资源。
优化策略:
- 增大 sort_buffer_size 参数的设置
- 增大 max_length_for_sort_data 参数的设置
- 少用 select *
当查询字段大小总和小于max_length_for_sort_data而且排序字段不是 TEXT | BLOB 类型时,会使用单路排序,否则使用双路排序。
GROUP BY 优化
- group by 实质是先排序后分组,遵照索引的最佳左前缀
- 当无法使用索引时,增大 sort_buffer_size 参数的设置+增大 max_length_for_sort_data 参数的设置
- where 高于 having,能写在 where 限定的条件就不要到 having 中限定
















本类排行
今日推荐






热门手游
-
港诡实录破解版

版本:1.0
大小:6.78MB
日期:2024-05-02
-
我也是大侠感恩节无限生命版

版本:1.3.1
大小:157.32MB
日期:2024-05-02
-
武林盟主无限寻宝免费版

版本:5.2.0
大小:165.53MB
日期:2024-05-02
-
暗黑传说魔域完整版

版本:7.4.0
大小:915.23MB
日期:2024-05-02
-
英雄复古神途完整版

版本:1.0.1.3800
大小:226.54MB
日期:2024-05-02
-
凯蒂猫世界2三丽鸥免费版

版本:v7.2.4
大小:1MB
日期:2024-05-02