MySQL索引及执行计划
时间:2022-03-16 11:47
索引
在mysql中称之为键, 一种数据结果, 帮助减少SQL语句经历的IO次数
一. Mysql 查找数据的两种方式
- 全表遍历扫描
- 通过索引查找算法进行遍历扫描
二. 索引作用
提供了类似书中目录的作用, 目的是为了优化查询三. 索引种类
根据不同的算法进行划分
- B树索引
- Hash索引
- R树
- Full text
- GIS
四. B+树的结构
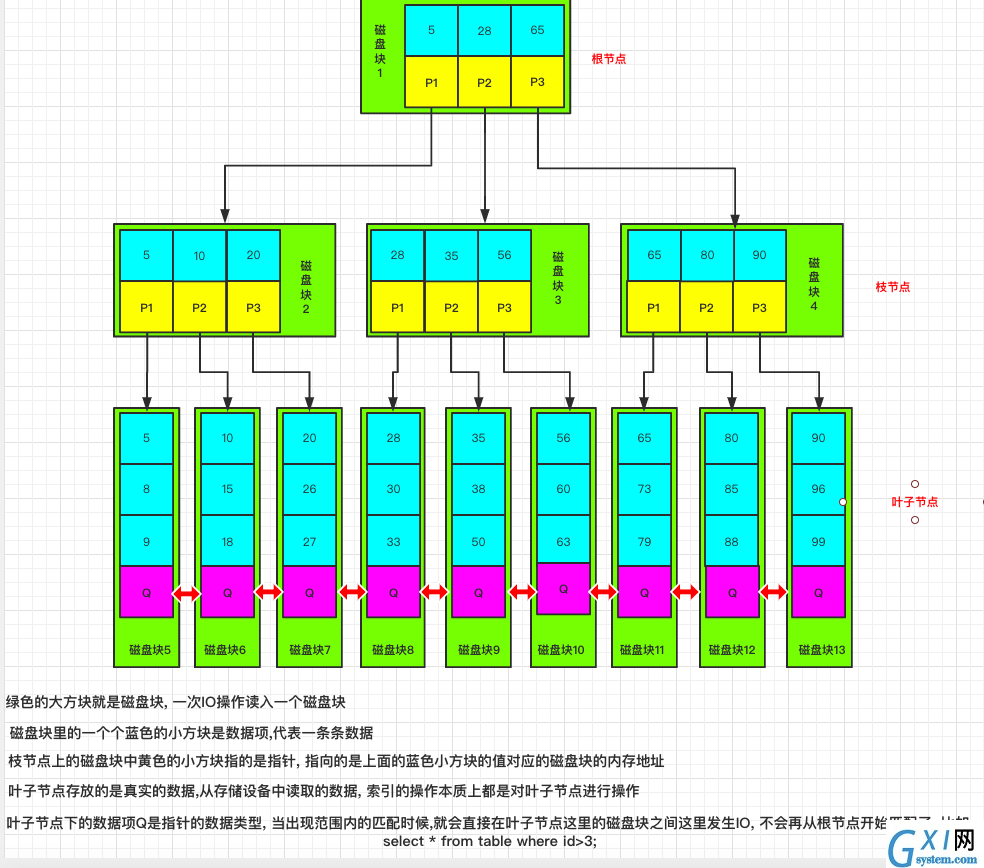
b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1(根节点)由磁盘加载到内存,此时发生一次IO,确定29是大于5和大于28这两个数据像,最后肯定是选择与29这个数更接近的28这个磁盘像并锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29大于28,所以只能选择28这个磁盘像并锁定磁盘块3的P1指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
b+树性质
1.索引字段要尽量的少:如果只需要检索一个id, 正常的只会进行3次IO, 而如果检索多个,则肯定是需要超过3次IO的
2.索引的最左匹配特性:当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
执行计划
















本类排行
今日推荐
-
逗拍56个民族服装特效模板免费版

版本:11.6.0
大小:105.33MB
日期:2024-04-27
-
甜美证件照正式版

版本:1.1.2
大小:60.41MB
日期:2024-04-27
-
复古老照片滤镜免费版

版本:1.0
大小:65.46MB
日期:2024-04-27
-
柠萌相机官方版

版本:1.0.0
大小:22.60MB
日期:2024-04-27
-
玩美修图照相机新版

版本:8081.18.12.12
大小:28.26MB
日期:2024-04-27
-
智邦国际ERP系统官方版

版本:v3206.001
大小:28.96MB
日期:2024-04-27
热门手游
-
硬卡车司机模拟器完整版

版本:v3.3.0
大小:169.5M
日期:2024-04-27
-
RiderSkills骑手技能正式版

版本:v1.3.0
大小:85.1M
日期:2024-04-27
-
QQ飞车新版

版本:v4.7.1.3029701
大小:33.6M
日期:2024-04-27
-
Wheelie Life2官方版

版本:v1.5
大小:104.7M
日期:2024-04-27
-
疯狂赛车竞技新版

版本:v1.0.1
大小:96.7M
日期:2024-04-27
-
仙域奇侠传正版

版本:1.0
大小:2.26MB
日期:2024-04-27